随机变量:X是定义与样本空间上的函数。
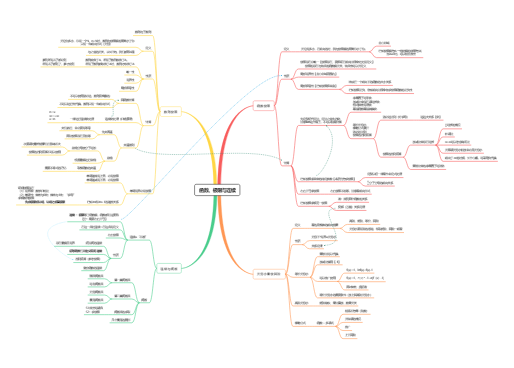
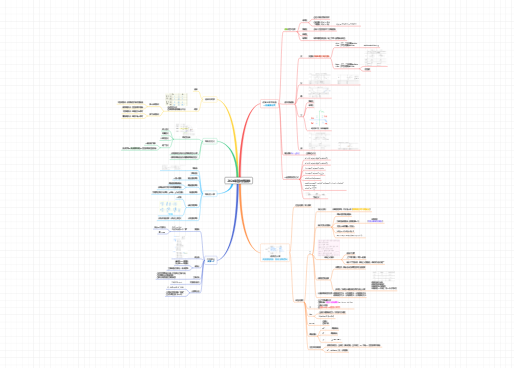
随机变量的分布函数 随机变量的分布函数的性质同时也是判断分布函数的必要条件。
分布函数的运算要关注两边的端点是否包含着范围内,右端点的概率同存在情况一致,左端点的概率与情况相反。
离散型随机变量:
1)做某件事次数是固定的,用n表示。(在 n次重伯努利试验中)
▶ 泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。(某个时间范围内,发生某件事情x次的概率是多大) ▶ 泊松分布是一种描述和分析稀有事件的概率分布,要观察到这类事件,样本含量n必须很大。它可以把大区间分成若干小区间,或把若干小区间合并成一个大区间(如研究交通事故的次数可以通过以月、年为单位统计)。
▶ 指在 n次重伯努利试验中,试验r次才得到第一次成功的机率。即前r-1次都失败,在第r次成功的概率。 判断是否是几何分布:
▶ 超几何分布是产品抽样检查中用的,其实,它是二项分布的变体。
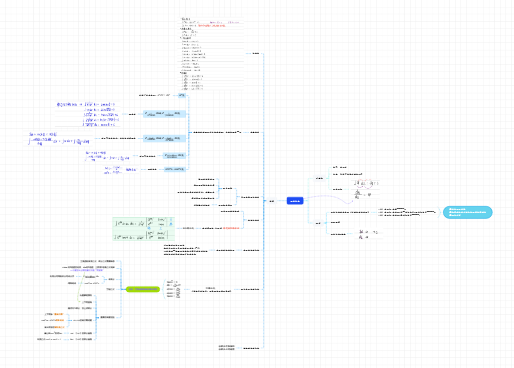
▶ 概率密度函数:用于直观地描述连续性随机变量(离散型的随机变量下该函数称为分布律),表示瞬时幅值落在某指定范围内的概率,因此是幅值的函数。连续样本空间情形下的概率称为概率密度,当试验次数无限增加,直方图趋近于光滑曲线,曲线下包围的面积表示概率,该曲线即这次试验样本的概率密度函数。
连续型随机变量的分布函数为连续函数,但不一定可导。
存在既非离散型又非连续型的随机变量。
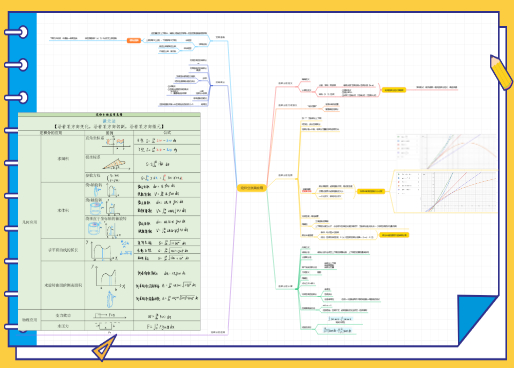
▶ 均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。 概率密度函数图像
分布函数图像
▶ 指数分布概率分布研究的是泊松过程的事件之间的时间间隔。如果每单位时间的事件数服从泊松分布,则事件之间的时间量遵循指数分布。
正态分布特征趋向的原因:因为我们研究的对象具有同质性,所以其特征往往是趋同的,即存在一个基准;但由于个体变异的存在,这些特征又不是完全一致,所以会以一定的幅度在基准的上下波动,从而形成了中间密集,两侧稀疏的特征。
标准正态分布
正态分布的性质:
【举例】