会议主题:
会议日期:
参会人员:
会议资料:
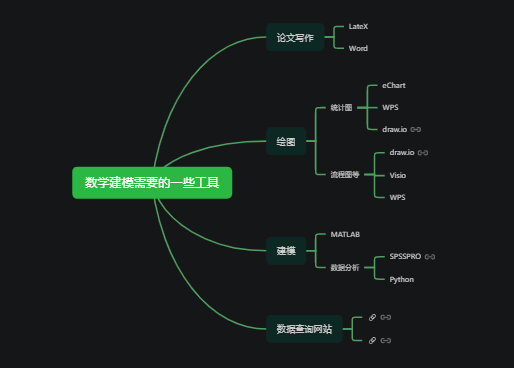
linprog
非线性规划
整数规划
最短路径
最小生成树
决策变量类型无要求但纬度较低,不能大范围搜索
优点:收敛速度快且跳出局部最优解能力强
缺点:决策变量维度较高时,算法收敛速度很慢
决策变量为离散变量,适用于比如整数规划,0-1规划
优点:跳出局部最优解能力强
缺点:收敛速度慢
类似于鸟群找食物,不断聚集
决策变量为连续的
缺点:跳出局部最优解能力弱
优点:收敛速度快
是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。 该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,例如通过构建评价指标(景色、费用,居住,饮食、旅途)对候选旅游地(桂林、黄山,北戴河)量化评价,进行选择.
步骤:构建层次结构模型;构建成对比较矩阵;层次单排序及一致性检验(即判断主观构建的成对比较矩阵在整体上是否有较好的一致性) ;层次总排序及一致性检验(检验 层次之间的一致性)。
改进方法:
(1)成对比较矩阵可以采用德尔菲法获得。
(2)如果评价指标个数过多(一般超过9个),利用层次分析法所得到的权重就有一定的偏差,继而组合评价模型的结果就不再可靠。可以根据评价对象的实际情况和特点,利用一定的方法,将各原始指标分层和归类,使得每i各类中的指标数少于9个。
优点:数据较少情况下定权,决策花费时间短
缺点:专家打分,主观性强
借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。
是根据评价对象与理想化目标的接近程度进行排序的方法,是一种距离综合评价方法。基本思路是通过假定正、负理想解,测算各样本与正、负理想解的距离,得到其与理想方案的相对贴近度。 用于企业管理、市场营销、投资决策等领域。主要适用于评价指标相对较多,指标间相互独立。
步骤:指标同向化、标准化并得到权重,得到加权后的规范化矩阵;确定正、负理想解;计算各样本距离正、负理想解的距离;计算各评价对象与最优方案的贴近程度
改进方法:
在TOPSIS当中,默认了各个评价指标所占的权重相同,但在实际的评价过程当中由于各种主观客观因素的影响,导致每一个评价指标所占的权重是有差异的:
1. 主观权重- -- 层次分析法(AHP)
2. 客观权重一- 熵权法
优点:该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
根据信息熵的定义,对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大, 该指标对综合评价的影响(即权重)就越大,如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度。 可利用各方案与最优方案之间关联度大小对评价象进行比较、排序。关联度越大,说明此较序列与参考序列变化的态势越一致,反之,变化态势则相悖。由此可得出评价结果。
步骤:建立原始指标矩阵;确定最优指标序列进行指标标准化或无量纲化处理;求差序列、最大差和最小差;计算关联系数;计算关联度。
改进方法: (1)采用组合赋权法:根据客观赋权法和主观赋权法综合而得权系数。
(2)结合TOPSIS法:不仅关注序列与正理想序列的关联度,而且关注序列与负理想序列的关联度|依据公式计算最后的关联度。
优点:该模型可以较好地解决评价指标难以准确量化和统计的问题,可以排除人为因素带来的影响,使评价结果更加客观准确。
缺点:要求数据有时间序列特性
指将效益型指标从小到大排序进行排名、成本型指标从大到小排序进行排名,再计算秩和比,最后统计回归、分档排序。通过秩转换,获得无量纲统计量RSR,以RSR值对评价对象的优劣直接排序或分档排序,从而对评价对象做出综合评价。
缺点:需要样本极多,易陷入局部最小值点
改进方法:
采用组合评价法:对用其它评价方法得出的结果,选取一部分作为训练样本,一部分作为待测样本进行检验,如此对|神经网络进行训练,知道满足要求为止,可得到更好的效果。
是一种交互式评价方法,可不断修改指标的权值,直到用户满意为止。
LSTM
短、中、长期的预测都适合。如传染病的预测模型、经济增长(或人口)的预测模型、Lanchester战争预测模型。难难难
给了几组数据,建立一个灰回归方程,求出方程中的几个参数,即可建立起来一个预测模型。 使用的三个条件:只适用于中短期预测,样本比较少,单调性数据。
步骤:做级比检验;建立灰色模型
步骤:导入实验数据;确定ARMA模型阶数;残差检验;出结果。
据自变量个数分为一元回归预测,多元回归预测,重点是找到对应的函数。
各类回归分析(线性/非线性/岭回归/lasso回归)
k-means聚类
分层聚类
BP神经网络
随机森林
支持向量机
朴素贝叶斯
Pearson相关性分析适用于服从正态分布的两定量变量,若两变量通过绘制散点图后发现存在线性趋势,可以通过计算Pearson相关系数来描述两变量的线性相关性。
输入:
两个或者两个以上的定量变量。
输出:两两变量之间是否呈现显著性相似以及相似的程度。
Spearman相关系数适用于定量变量或定序变量两两之间的相关分析,利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,当我们变量中至少存在一个有序变量时,可使用Spearman系数来描述两变量的相关性。对于均为定量数据亦可计算Spearman相关系数,但统计效能要低一些。
输入:
两个或者两个以上的定量变量或有序定类变量(有序定类变量可用数值代替)。
输出:两两变量之间是否呈现显著性相似以及相似的程度。
Kendall's tau-b系数适用于定序变量两两之间相关分析,其不要求变量满足正态分布条件,当我们变量中均为有序变量时,可使用Kendall's tau-b系数来分析变量间的相关性。
输入:
两个或者两个以上的有序定类变量(有序定类变量可用数值展示)。
输出:两两变量之间是否呈现显著性相似以及相似的程度。
一致性检验
子主题
T检验
F检验(方差齐性检验)
卡方分析
判断函数是否为凸函数(画一条线,线上的点在封闭图形内或者在抛物线上方)
非凸函数用启发式算法来求