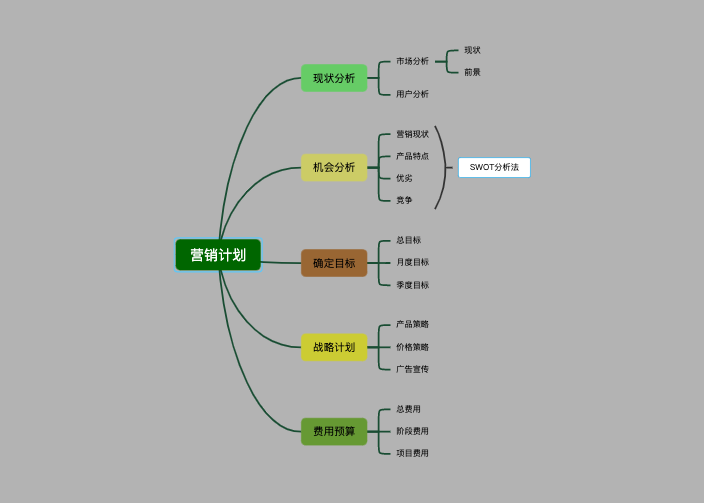
LPWAN:低功耗广域网络,它是一种远距离低功耗的无线通信网络技术,主要包含NB-IOT、LoRa、Sigfox、eMTC四种 semtech公司开发的一种低功耗局域网无线标准,其名称“LoRa”是远距离无线电(Long Range Radio),它最大特点就是在同样的功耗条件下比其他无线方式传播的距离更远,实现了低功耗和远距离的统一,它在同样的功耗下比传统的无线射频通信距离扩大3-5倍。
NB-IOT全称之为Narrow Band-Internet of Things,窄带物联网;基于蜂窝网络,可直接部署于GSM网络、UMTS网络或LTE网络,部署成本低;它的传输距离可达十几公里,每个网络单元可以支持接入50000个设备终端。速度方面,NB-IoT的频射网络带宽为200kHz。传输速率一般在160kbps-250kbps之间;又由于NB-IOT通讯结构及设备本身的数据接收及上报模式的设置等因素,NB-IOT通讯常会具有10s内的传输延时。
Sigfox是一种低成本,可靠,低功耗的解决方案,用于连接传感器和设备。通过专用的低功耗广域网络,致力于连接千千万万的物理设备,并使物联网真正发生。
eMTC,全称是 LTE enhanced MTO,是基于LTE演进的物联网技术。为了更加适合物与物之间的通信,也为了更低的成本,对LTE协议进行了裁剪和优化。eMTC基于蜂窝网络进行部署,其用户设备通过支持1.4MHz的射频和基带带宽,可以直接接入现有的LTE网络。eMTC支持上下行最大1Mbps的峰值速率,可以支持丰富、创新的物联应用。
RFID
传感器
嵌入式系统
为应用软件提供接口,使应用程序能够使用网络服务。
数据的解码和编码
建立、管理和终止表示层实体之间的会话连接
负责建立端到端的连接,保证报文在端到端之间的传输。提供可靠及不可靠的传输机制。
路由器-IP地址
作用:在不可靠的物理链路上,提供可靠的数据传输服务,把帧从一跳(结点)移动到零一跳(节点) 交换机-物理地址(MAC地址)
物理层标准规定了信号,连接器和电缆的要求
1.网络发现。在边缘计算中,由于计算服务请求者的动态性,计算服务请求者如何知道周边的服务,将是边缘计算在网络层面中的一个核心问题.传统的基于DNS的服务发现机制,主要应对服务静态或者服务地址变化较慢的场景下.当服务变化时,DNS的服务器通常需要一定的时间以完成域名服务的同步,在此期间会造成一定的网络抖动,因此并不适合大范围、动态性的边缘计算场景。
2.快速配置。在边缘计算中,由于用户和计算设备的动态性的增加,如智能网联车,以及计算设备由于用户开关造成的动态注册和撤销,服务通常也需要跟着进行迁移,而由此将会导致大量的突发网络流量。与云计算中心不同,广域网的网络情况更为复杂,带宽可能存在一定的限制.因此,如何从设备层支持服务的快速配置,是边缘计算中的一 个核心问题。
3.负载均衡。边缘计算中,边缘设备产生大量的数据,同时边缘服务器提供了大量的服务.因此,根据边缘服务器以及网络状况,如何动态地对这些数据进行调度至合适的计算服务提供者,将是边缘计算中的核心问题。
解决方案:NDN和SDN。首当其冲面对的就是如何寻找服务,以完成计算路径的建立。命名数据网络(named data networking,NDN)是一种将数据和服务进行命名和寻址,以P2P和中心化方式相结合进行自组织的一种数据网络。而计算链路的建立,在一定程度上也是数据的关联建立,即数据应该从源到云的传输关系.因此,将NDN引入边缘计算中,通过其建立计算服务的命名并关联数据的流动,从而可以很好地解决计算链路中服务发现的问题。
解决的问题:1)计算资源的隔离,即应用程序间不能相互干扰;2)数据的隔离,即不同应用程序应具有不同的访问权限。
解决方案:采用Docker技术实现应用的相互隔离
通用处理器和异构计算硬件并存的模式,边缘计算平台通常针对某一类特定的计算场景设计,处理的负载类型较为固定,故目前有很多前沿工作针对特定的计算场景设计边缘计算平台的体系结构.
边缘计算操作系统向下需要管理异构的计算资源,向上需要处理大量的异构数据以及多用的应用负载,其需要负责将复杂的计算任务在边缘计算节点上部署 、调度 及迁移从而保证计算任务的可靠性以及资源的最大化利用。与传统的物联网设备上的实时操作系统Contikt和FreeRTOS不同,边缘计算操作系统更倾向于对数据、计算任务和计算资源的管理框架。
例子:机器人操作系统(robot operating system, ROS) ,EdgeOSH则是针对智能家居设计的边缘操作系统,
使硬件设备更好地执行以深度学习算法为代表的智能任务是研究的焦点,也是实现边缘智能的必要条件.
在云数据中心,算法执行框架更多地执行模型训练的任务,它们的输人是大规模的批量数据集,关注的是训练时的迭代速度、收敛率和框架的可扩展性等.而边缘设备更多地执行预测任务,输人的是实时的小规模数据,由于边缘设备计算资源和存储资源的相对受限性,它们更关注算法执行框架预测时的速度、内存占用量和能效。
解决方案:2017年,谷歌发布了用于移动设备和嵌人式设备的轻量级解决方案TensorFlow Lite,它通过优化移动应用程序的内核、预先激活和量化内核等方法来减少执行预测任务时的延迟和内存占有量.Caffe2 是Caffe的更高级版本,它是一个轻量级的执行框架,增加了对移动端的支持.此外,PyTorch和 MXNet等主流的机器学习算法执行框架也都开始提供在边缘设备上的部署方式。
边缘计算场景下,边缘设备时刻产生海量数据,数据的来源和类型具有多样化的特征,这些数据包括环境传感器采集的时间序列数据、摄像头采集的图片视频数据、车载LiDAR的点云数据等,数据大多具有时空属性。构建一个针对边缘数据进行管理、分析和共享的平台十分重要。
案例:以智能网联车场景为例,车辆逐渐演变成一个移动的计算平台,越来越多的车载应用也被开发出来,车辆的各类数据也比较多。由.Zhang等人提出的OPenVDAP是一个开放的汽车数据分析平台,如下图3所示,Open VDAP分成4部分,分别是异构计算平台(VCU )、操作系统(EdgeOSv)、驾驶数据收集器(DDI)和应用程序库(libvdap),汽车可安装部署该平台,从而完成车载应用的计算,并且实现车与云、车与车、车与路边计算单元的通信,从而保证了车载应用服务质量和用户体验.因此,在边缘计算不同的应用场景下,如何有效地管理数据、提供数据分析服务,保证一定的用户体验是一个重要的研究问题。
7.安全和隐私
为保障系统性能,主要有不同业务在网络中出现,各种节点间的协调方案,网络的选择以及节能配置方法等,多网络组织形成一个体系较密集异构。
自组织网络技术解决的关键问题主要有:①网络部署阶段的自规划和自配置;②网路维护阶段的自优化和愈合。
在网络中添加新的层次,即智能虚拟网络。
D2D通讯即设备到设备通讯,是一种基于蜂窝系统的近距离数据直接传输技术,标准化组织3GPP已经把D2D技术列入新一代移动通信系统的发展框架中,成为第五代移动通信的关键技术之一。
广义M2M,主要指机器与机器之间,人与机器之间以及移动网络与机器之间的通讯,涵盖了所有实现人、机器、系统之间通讯的技术,狭义上M2M,仅仅指机器与机器之间。
6、信息中心网络:以信息为中心
7、移动云计算
软件定义无线网络就是用一个通用的模式来定义和控制无线网络,让网络系统变得更加简单。
情景感知技术是采用了传感器等相关技术的信息资源系统,使得终端设备具有感知当前情景的能力,并分析位置、用户行为等情景信息,主动为用户提供合适的服务。它具有适用性、及时性、预测性等特点。让互联网变得更加主动和智能,及时推送用户想知道的信息。
边缘计算就是将带有缓存、计算处理能力的节点部署在网络边缘,与移动设备、传感器和用户紧密相连,减少核心网络负载、降低数据传输时延。
针对不同业务场景对网络功能需求的不同,如果为这些特定的场景部署专有网络,这个网络只包含这个运用场景需要的功能,那么服务的效率将大大提高,运用场景所需要的网络性能也能够得到保障,网络的运维将变得简单。
1.国家顶级节点-Handle技术+异构兼容互操作 武汉、广州、重庆、上海、北京
灾备节点:南京、成都
标识解析二级节点建设也已在广东、福建、贵州、浙江、江苏、天津、北京、重庆、湖北等地陆续启动上线。目前已累计完成47个二级节点部署,其中覆盖行业包括船舶、供应链、医疗、建筑材料、航天设备等。
二级节点清单:
3.国家及行业标准
4.编码技术URL、Handle、OID、Ecode
条形码
二维码
RFID
数字码
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 [1] 。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。
数据清洗就是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
数据字典(Data dictionary)是一种用户可以访问的记录数据库和应用程序源数据的目录。主动数据字典是指在对数据库或应用程序结构进行修改时,其内容可以由DBMS自动更新的数据字典。
主题数据仓库
数据API
虚拟化-云管
存储及计算集群
K8S+docker(虚拟化运行环境,统一应用管理)
微服务
DevOps
机理模型(白箱):根据对象、生产过程的内部机制或者物质流的传递机理建立起来的精确数学模型。它是基于质量平衡方程、能量平衡方程、动量平衡方程、相平衡方程以及某些物性方程、化学反应定律、电路基本定律等而获得对象或过程的数学模型。机理模型的优点是参数具有非常明确的物理意义。这类模型存在在各行各业,需要充分的输入条件,通过模型得到输出,可以模拟整个过程。 类比分析法:根据一些物理定律,经济规律,数学原理等建立不同事物之间的类比关系,建立问题的数学模型。
针对实际问题-----了解问题背景----分析问题-----明确相关因素和参数-----分析其内在关系—用适当数学方法—建立关联模型–选用实际数据–确定未知数据—求解模型—用结果解释实际问题—用实际数据或模拟检验模型—进一步扩展模型。
参考文章:https://blog.csdn.net/weixin_39334790/article/details/119133652
机理与机制:
概念数据模型是按照用户的观点来对数据和信息建模,主要用于数据库设计。概念模型主要用实体联系方法表示,所以也称E-R模型。
基本数据模型:基本数据模型是按照计算机系统的观点对数据和信息建模,主要用于DBMS的实现。基本数据模型是数据库系统的核心和基础。基本数据模型通常由数据结构、数据操作和完整性约束三部分组成。其中数据结构是对系统静态特性的描述,数据操作是对系统动态特性的描述,完整性约束是一组完整性规则的集合。 用树型结构表示实体类型及实体间联系。层次模型的优点是记录之间的联系通过指针来实现,查询效率较高。层次模型的缺点是只能表示1:n联系,虽然有多种辅助手段实现m:n联系,但较复杂,用户不易掌握。由于层次顺序的严格和复杂,使得数据的查询和更新操作很复杂,应用程序的编写也比较复杂。
用有向图表示实体类型及实体间联系。网状模型的优点是记录之间的联系通过指针实现,m×n联系也容易实现,查询效率高。其缺点是编写应用程序比较复杂,程序员必须熟悉数据库的逻辑结构。
用表格结构表达实体集,用外键表示实体间联系,其优点有:
低代码开发-工业APP
“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)。 图(Graph)是由节点(Vertex)和边(Edge)来构成,多关系图一般包含多种类型的节点和多种类型的边。实体(节点)指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系(边)则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性
知识图谱是人工智能很重要的一个分支, 人工智能的目标为了让机器具备像人一样理性思考及做事的能力 ->
实体命名识别(Name Entity Recognition)
关系抽取(Relation Extraction)
指代消解(Coreference Resolution)
1.依托发达地区产业图谱进行对比分析
2.
阿里云工业大脑开放平台目前包含以下几款核心产品。
物联网设备接入
数据API接入
人工填报
网络互联
数字孪生的基础
工控安全
数据安全
网络安全