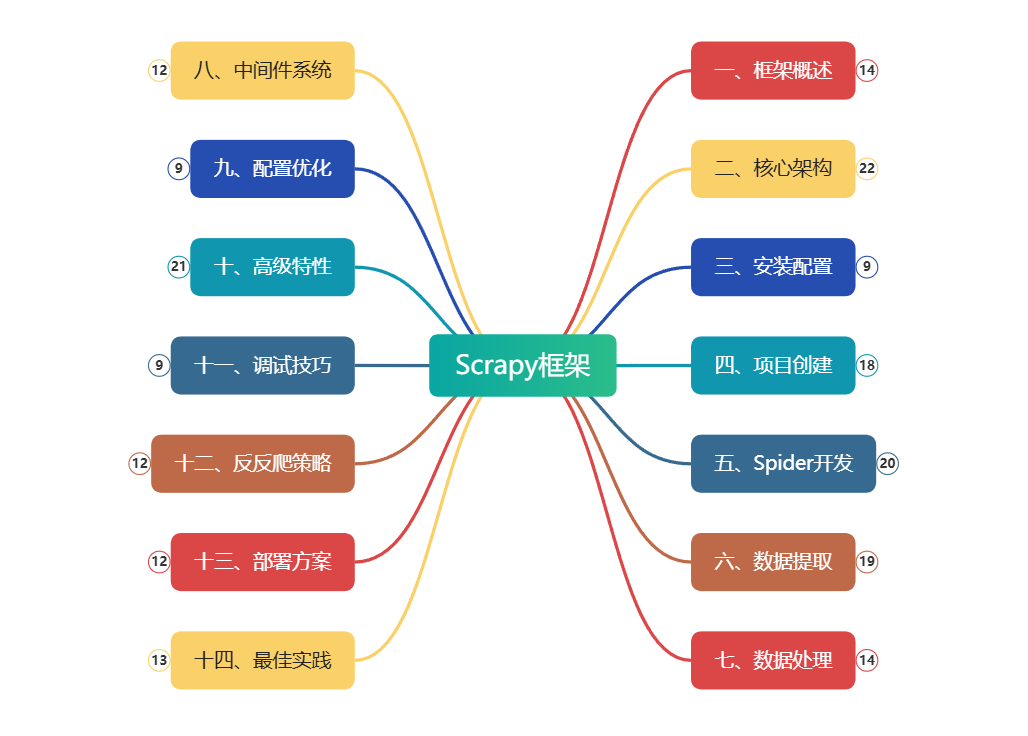
深度学习是学习样本数据的内在规律和表示层次
深度学习是一个复杂的机器学习算法
输入层:将数据输入给神经网络
隐含层:增加网络深度和复杂度,隐含层的节点数是可以调整的,节点数越多,神经网络表示能力越强,参数量也会增加。
通常隐含层会比输入层的尺寸小,以便对关键信息做抽象,激活函数使用常见的Sigmoid函数。
输出层:输出网络计算结果,输出层的节点数是固定的。如果是回归问题,节点数量为需要回归的数字数量。如果是分类问题,则是分类标签的数量。
所有神经元参与运算,计算充分,特征提取比较充分,捕获所有特征
前向传播和反向链式求导方法
分类问题使用的交叉熵损失函数的意义
Dropout等解决过拟合问题的方法
使用DNN网络模型解决其他类似问题
经典网络模型(Alexnet、VGG、ResNet等)
特征平移后出现在图片不同位置,卷积核都会找到该特征,特征检测所做的操作一样。
减少参与运算的参数量,帮助进行特征提取的技术,提取最关键的内容
缓解卷积层对位置的过度敏感
减少冗余
降低图像分辨率,从而减少参数量
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
卷积计算=特征抽取
sigmoid 二分类/多标签分类
softmax 多分类
Relu
(1)具有局部区域连接、权值共享、降采样的结构特点
(2)卷积指的是神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理,这种做法加强了图片信息的连续性。 使得神经网络能看到图形, 而非一个点。具有平移不变性。
(3)池化操作:对于输入的图片,选择最大池化或平均池化对其进行压缩,以加快神经网络的运算速度。在卷积神经网络中通常会在相邻的卷积层之间加入一个池化层,池化层可以有效的缩小参数矩阵的尺寸,从而减少最后连接层的中的参数数量。
池化的作用:对数据进行下采样,减少运算参数量;降低了图像的分辨率,加快计算速度和防止过拟合。
(4)http://t.csdn.cn/65hQf
经过卷积层的特征提取与池化层的降维后,将特征图转换成一维向量送入到全连接层中进行分类和回归的操作
网络输入输出数据类型
利用Paddle API接口使用经典网络训练和测试数据
解决图像分类问题
多层神经网络
深度神经网络
整型 int
浮点型 float
复数 complex
把字符串转成一个个字节
一个字符对应两个字节
三引号创建的字符串可以跨越多行
引号前加u表示创建的是一个Unicode字符串
字符串查找,查找到返回开始的索引值否则返回-1
字符串反向查找,返回字符串最后一次出现的位置否则返回-1
字符串替换
剔除两端空白
列表中元素的类型可以不相同,支持数字、字符串、列表
列表之间的元素用逗号分隔开,可以用+操作符进行拼接,使用*表示重复
列表有切片操作与字符串类似
列表删除元素del 如:del a[1]
列表长度len len(a)
列表相加 a+b
列表复制 a*2
包含判断 if 3 in a:pass
元组的元素不能修改
任意无符号的对象,以逗号隔开,默认为元组
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用:
元组可以使用下标索引来访问元组中的值
len(a)
max(a)
min(a)
tuple(iterable)将可迭代系列(如列表)转换为元组
同一个字典中,键必须是唯一的
a[键名]
len(dict),str(dict),type(dict)
set是一组key的集合
要在函数内给一个全局变量赋值时,需要先用global关键字声明变量,否则编译器会尝试新建一个同名的局部变量
大小写英文、数字、下划线,且不能以数字开头
函数内定义的变量
input函数的返回值类型:字符串
+ - * / % ** //
赋值运算符
比较运算符
&
|
相同为0,相异为1
按二进制位进行"取反"运算 理解:0的为1,1的为0 举例: ~6
6 => 0000 0000 0000 0110
~ 1111 1111 1111 1010 转换成十进制也就是-7
<<
>>
a为False,则返回False否则返回b的计算值
a为True则返回a的值,否则返回b的计算值
a为True返回False,a为False返回True
a在b就返回True
a不在b就返回True
is
is not
类似id(x)==id(y),id(x)函数用于获取对象内存定制
Python指定任何非0和非空值为True,0或者Node为False
条件判断和循环
单行注释#
多行注释多个#,''' '''或者""" """
使用反斜杠\实现分行
if elif else + :
注意文件的读取形式
[1 2 3]
[[1,2]
[3,4]]
np.zero([10,10])
np.ones([10,10])
返回数组中元素总个数
返回数组各个维度对应长度
numpy.linspace(开始,结束,总个数)
创建10行10列的数组(范围在0-1之间)
生成均匀分布随机数,指定随机数取值范围和数组形状
创建指定范围内的一个整数
np.random.randn(),产生均值0,方差1的正态分布随机数,参数代表它的形状
np.random.standard_normal(),产生标准正态分布随机数,参数代表它的形状
np.random.normal(loc= ,scale= ,),产生正态分布的随机数,参数代表均值/标准差/形状
np.random.shuffle(a)
a = np.arange(30)
b = np.random.choice(a, size=5)
任何修改都会直接反映到源数组上
还有一种方式是传入一个以逗号隔开的索引列表来选取单个元素
sum()
mean()
axis参数读取方式
cumsum(0)按行进行求和(向下)
cumprod(1)按列进行乘积(向右)
两矩阵相乘
进行运算的两个元素个数必须相同
元素可以与标量分别进行运算
主要实现加载数据、整理数据、操作数据、构建数据模型、分析数据环节
提供一个带有默认标签的DataFrame对象
能够从不同格式的文件中加载数据然后转换为可处理的对象
能够按行、列标签进行分组,并对分组后的对象执行聚合和转换操作
能够方便实现数据归一化操作和缺失值处理
能够对数据列进行增删改操作
能够处理不同格式的数据集、提供多种处理数据集的方式
index和value 与字典不同的是Series允许索引重复
Series的字符串表现形式为:索引在左边,值在右边
如果没有为数据指定索引,则自动创建一个0到N-1 (N为数据的长度)的整数型
索引可以通过Series的 values和 index属性获取其数组表示形式和索引对象
与普通numpy数组相比﹐可以通过索引的方式选取Series中的单个或一组值
它会在算术运算中自动对齐不同索引的数据
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值﹑字符串﹑布尔值等)
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
跟其他类似的数据结构相比(如R语言的data.frame ) , DataFrame 中面向行和面向列的操作基本上是平衡的
DataFrame 中的数据是以一个或多个二维块存放的(而不是列表﹑字典或别的一维数据结构)
如果指定了列顺序,则 DataFrame的列就会按照指定顺序进行排列
跟原Series一样,如果传入的列在数据中找不到,就会产生NAN值
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个 Series,返回的Series拥有原DataFrame相同的索引,且其name属性也已经被相应地设置好了
列可以通过赋值的方式进行修改
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配
如果赋值的是一个Series,就会精确匹配DataFrame的索引,所有空位都将被填上缺失值
设置了DataFrame的 index和 columns的name属性,则这些信息也会被显示
跟Series一样, values属性也会以二维ndarray的形式返回DataFrame中的数据
Series一维数组
DataFrame二维数组
如果DataFrame各列的数据类型不同,则数组的数据类型就会选用能兼容所有列的数据类型
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)
构建DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index
Index对象是不可修改的,因此用户不能对其进行修改
读取数据库中的数据
data.tail()打印数据的最后一行
data.loc[行数,列名],打印该行列名为...的列
data.loc[range(4,6)],打印4到5行的数据子集,左闭右开原则
data.loc[行数,列名]=newvalue
Matplotlib(绘制各类图形)
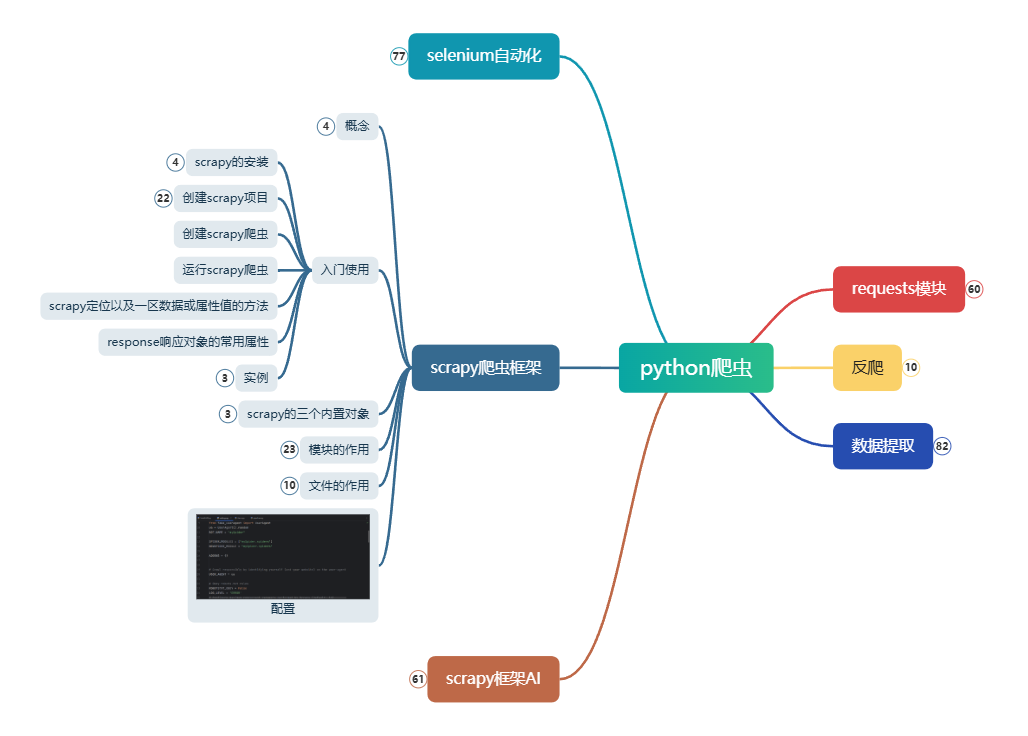
reques.get()
反爬措施
数据清洗和预处理
精准模式
Jieba.cut(str,cut_all=True)
全模式
Jieba.cut_for_search(str)
搜索引擎模式
迭代器如何打印?
jieba.cut返回的是一个列表
jieba.load_userdict(词典路径)
词语 词频 词性
人工智能 100 nz
计算机学院 100 nt
seg_list2=jieba.cut(text)
print(",".join(seg_list2))
#添加词
jieba.add_word(‘计算机科学与技术')
#删除词
jieba.del_word(‘的’)
#修改词频
jieba.suggest_freq((‘新', ‘开设'), True)
import jieba.posseg as pseg
words =pseg.cut("我爱北京天安门")
for w in words:
print (w.word,w.flag)
含义:假设某一个函数,使其能尽可能的代表数据的分布。
含义:用来度量模型的预测值f (x)与真实值Y的差异程度的运算函数
将具有相关关系的自变量与因变量之间的数量关系进行测定
一元回归分析
多元回归分析
测定相关关系的密切程度
建立回归方程
利用回归模型进行预测
非线性回归
一般把作为估测依据的变量叫做自变量
待估测的变量
反映自变量和因变量之间联系的数学表达式
要预测的真实事物(y)
用于描述数据的输入变量(x1,x2,....xn)
用于描述对最终预测结果产生影响的因子的各些特性
用于训练标签
用于对新数据做出预测
检查多个样本并尝试找出可最大限度地减少损失的模型,这一过程称为经验风险最小化
首先对权重w和偏差b进行初始猜测
然后反复调整这些猜测
直到获得损失可能最低的权重和偏差为止
不断迭代,直到总体损失不再变化或至少变化极其缓
慢为止
通过有标签样本来学习(确定)所有权重和偏差的理想值
训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差
损失是对糟糕预测的惩罚:损失是一个数值,表示对于单个样本而言模型预测的准确程度
即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大
梯度是矢量,具有方向和大小
用梯度乘以一个称为学习速率(有时也称为步长)的标量以确定下一个点的位置
和SGD时的情形相比,可以更快地朝×轴方向靠近,减弱“之”字形的变动程度。
特点: AdaGrad可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
在开始学习过程之前设置值的参数,不是通过训练得到的参数数据
典型超参数:学习率、神经网络的隐含层数量
y的预测值,输入是x
输入是预测值,label是真实值
保存模型路径
输入变量
输出变量,通过输出变量即可得到模型的预测结果
模型执行器
创建推测用的执行器
fluid.io.load_inference_model(模型训练路径,预测的执行器)
推理的项目
在推理的项目中提供数据的变量名称
推断结果
定量输出称为回归,或者说是连续变量预测
获取预测数据
使用算法解决回归类问题,预测连续值
得到某种表达式
将新的值带入表达式中进行计算
从给定的有标注的训练数据集中学习出一个函数,当有新的数据时可以使用这个函数进行预测结果
没有标注的训练数据集,根据样本间的统计规律对样本集进行分析
分类与聚类的区别
结合(少量的)标注训练数据和(大量的)未标注数据进行数据的分类学习
聚类假设
流形假设
对经典网络结构的理解和记忆
利用预训练模型基于新数据集迁移学习新的知识并解决新问题
外部环境对输出只给出评价信息而非正确答案,学习机通过强化受奖励的动作来改善自身的性能。
线性回归、神经网络、卷积神经网络、循环神经网络、生成对抗网络
数据清洗/特征选择
确定算法模型/参数优化
结果预测
深度学习模型的选择、构建和应用
支持向量机的基本原理,解决分类问题预测离散值