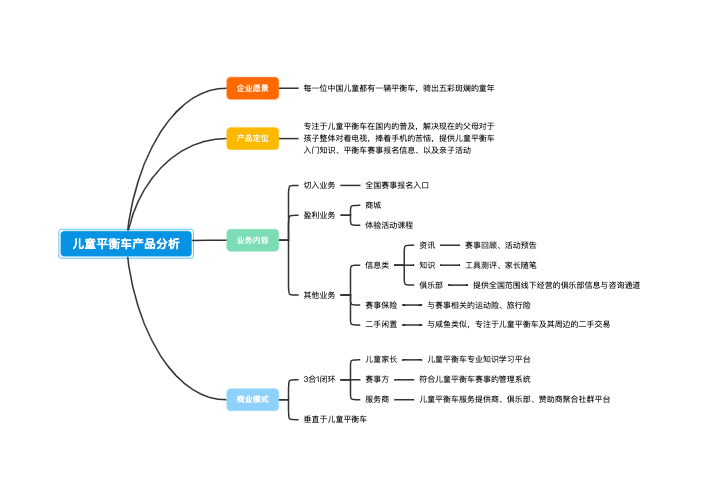
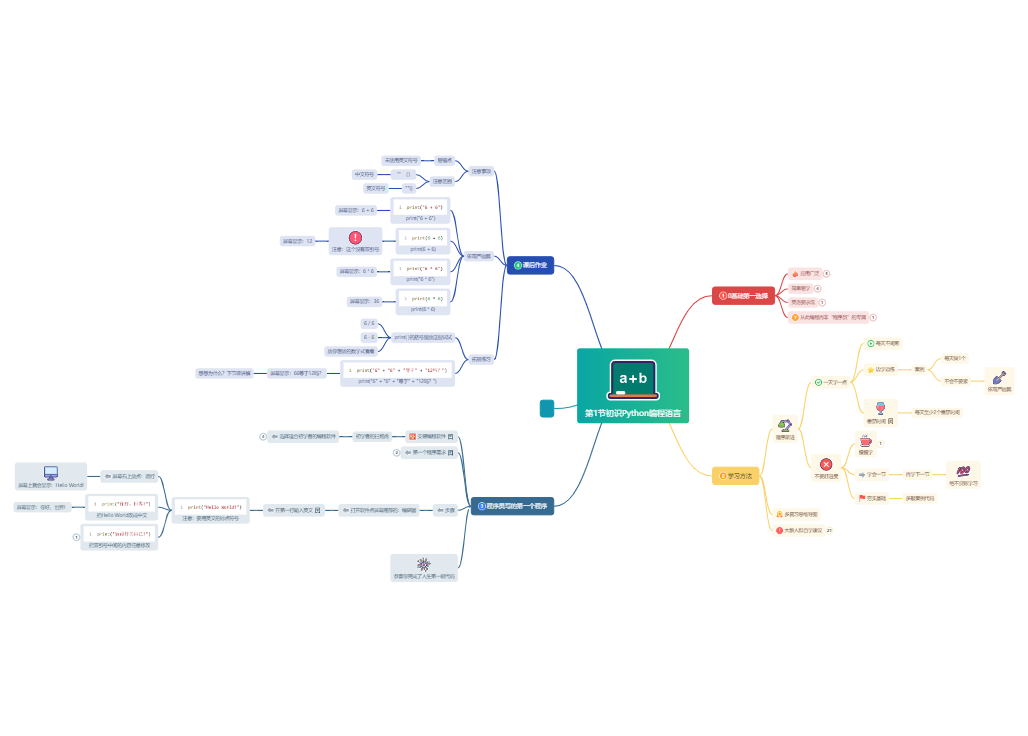
也称为列举法、穷举法,是暴力策略的具体体现。进行归纳推理时逐个考察了所有可能的情况,根据判断条件保留合适的舍弃不合适的,得出一般结论
确定枚举量(简单变量或数组)
确定枚举范围设置枚举循环
确定筛选条件
设计枚举程序并运行调试
有明确的范围要求,应用选择结构实施判别和筛选,在循环体中完成运算操作
没有明确的范围限制,可根据条件试探性地从某一起点开始增值枚举,对每个数进行操作和判断,满足条件时输出结果
确定解题范围,不遗漏不重复任何一个解
判定正确的解题方法
尽量缩小可能解的范围
在函数的定义中又调用自身的的方法
递归算法通常把一个大的复杂问题转化为一个小问题和多个与原问题相似的规模变小的问题
函数调用自身
函数调用其它的递归函数
需要解决的问题可以转化为一个小问题和多个与原问题求解方法相同,数量不同的问题
调用递归的次数有限
必须有结束条件来终止递归
公式、数列、概念的定义是递归的,如求n!、斐波那契数列等
单链表,在结构体自身定义中调用它自身
二叉树
问题的求解方法是递归的
递归的终止条件,一般格式为f(s1)=m;
f(n)的值与f(n-1)之间的关系,一般格式为f(sn)=g(f(sn-1),x)
为了存放每次调用的数据,系统设置了一个名叫系统栈的东西存放每次调用的返回地址和参数值(即一个栈帧),此次调用的数据集合可理解为一个栈元素,再次存入系统栈中,执行下一次调用。当调用函数执行完毕后,对应栈帧弹出(栈元素出栈),返回函数值,控制转到其对应的返回地址继续执行。
递归执行是通过系统栈实现的
每递归调用一次就需要将参数、局部变量和返回地址等作为一个栈元素进栈一次,进栈元素个数极大值被称为递归深度,n越大,递归深度越深
每次遇见递归出口或调用结束一次,就需退栈一次并恢复参数值,随着递归执行完毕,栈也清空了
void f(int n)
{
if(n<1) rturn;
else
{ printf("调用f(%d)前,n=%d\n",n-1,n;
f(n-1);
printf("调用f(%d)后,n=%d\n",n-1,n;
}
}
执行f(4)输出结果
调用f(3)前,n=4
调用f(2)前,n=3
调用f(1)前,n=2
调用f(0)前,n=1
调用f(0)后,n=1
调用f(1)后,n=2
调用f(2)后,n=3
调用f(3)后,n=4
解释:若{p(1),p(2),p(3),p(4),...}是命题序列,且满足以下性质,则所有命题为真
p(1)为真
任何命题均可以从前一个命题推导得出
解释:若{p(1),p(2),p(3),p(4),...}是命题序列,且满足以下性质,则对于其他自然数,该命题序列均为真。
p(1)为真
任何命题均可以从前面所有命题推导得出
先自上而下将问题分解,求解f(sn)转化为求解f(sn-1)和一个常量cn-1,即将一个sn状态转化为sn-1状态和一个常状态cn-1来间接求解,求解f(sn-1)的方法和环境与求解f(sn)的方法和环境时相似的,尽管f(sn-1)还未解决,但向解决目标靠近了一步,这就是一个"量变",如此达到递归出口时便发生的"质变",自下而上求值、合并,递归问题解决了。
子主题1
对原问题f(sn)进行分析,抽象出合理的较小问题f(sn-1)
每次递归调用的问题规模都应有所缩小
假设f(sn-1)是可解的,在此基础上确认f(sn)的解,即给出f(sn)与f(sn-1)的关系
相邻两次递归调用之间有紧密联系,前一次要为后一次递归调用做准备,通常是前一次递归调用输出作为后一次递归调用的输入
确认一个特定情况(如f(1)或f(0)的解,由此作为递归出口
再问题规模极小时必须直接给出问题解而不再进行递归调用,因此每次递归调用都是有条件的,无条件的递归将会成为死循环不能正常结束
采用递归方式定义的数据结构
递归数据结构中包含的递归运算
D={di}(1<=i<=n,共n个元素) 给定二叉树及其子树的集合
Op={opj} (1<=j<=m,共m个基本递归运算) 基本递归运算的集合
对于任意di∈D,都有opj(di)∈D,递归运算符具有封闭性
op1(p)=p->lchild
op2(p)=p->rchild
由基本递归运算符构成
设计不带头结点的单链表递归算法,通常设求解以L为首节点指针的整个单链表的功能为大问题,设除首节点以外的节点构成的单链表(L->next)的相同功能为小问题
通常单链表、双向链表、循环链表都带有头节点,是链表的起始位置,用于存放空指针来实现增删改查操作,这样会浪费一个链表空间;不带头结点意思是空指针不占用链表的存储空间,链表的起始位置存放着链表的第一个数据
通常设求解以b为根节点的整个二叉树的某功能为大问题,而设求解其左、右子树的相同功能为小问题,由大小问题之间的解关系得到递归体。递归出口通常考虑二叉树为空或者只有一个节点
给出一个带有参数n的问题,采用归纳思想设计递归算法,如果知道如何求解带有参数k(小于n)的同样问题(假设归纳),呢么整个问题就转化为如何把求解带有参数n的问题,转化成带有参数k的多个问题,归纳出大小问题之间的递推关系
简单选择排序
冒泡排序
两种排序方法都是将排序集合a[0,1,2...n-1]分为有序区和无序区两个部分,有序区的所有元素都不大于无序区中的元素,经过n-1次排序,每趟排序采用不同的方式将无序区的最小元素移动到无序区的开头
int fib(int n){
if (n<2) {
return n;
} else {
return fib(n-1) + fib(n-2);
}
}
会进行无意义的重复运算,计算重复值
将问题转换为可加数列,每一项的和等于前两项的和相加
int fib(int n){
return additiveSequence(n, 0, 1);
}
int additiveSequence(int n, int t0, int t1){
if (n==0) return t0;
if (n==1) return t1;
return additiveSequence(n-1, t1, t0+t1);
}
#include
#include
using namespace std;
long fib(long n){//计算双递推摆动数列
if (n==1) return 1;
else if(n%2==0)
return fib(n/2)+1;
else
return fib((n-1)/2)+fib((n-1)/2+1);
}
int main() {
long n,s=0;
cout <<"请输入您要求的整数和第n个整数";
cin >> n;
for(int i=1;i<=n;i++)
s=fib(i)+s;
cout << s << endl;
system("pause");
return 0;
}
递推是按照一定的规律来计算序列中的每个项,通常是通过计算前面的一些项来得出序列中的指定项的值。其思想是把一个复杂的庞大的计算过程转化为简单过程的多次重复。即通过已知条件,利用特定关系得出中间推论,直至得到结果的算法。
递推时顺着结果推结果
递归又称为逆推法,是顺着过程推过程,推到最终结果反过来求中间结果最终得答案
定义问题的状态:将原始问题划分为多个阶段,并将每个阶段的状态定义清楚。状态是解决问题所需的关键信息,也是动态规划算法的核心。
定义状态转移方程:根据问题的最优子结构性质,将原始问题的解表示为子问题的解之间的关系,即状态转移方程。状态转移方程描述了问题从一个状态转移到另一个状态时的转移规则。
初始化边界状态:根据问题的具体情况,确定初始阶段的状态,并设置其初始值。
通过状态转移方程递推求解:根据状态转移方程,从初始阶段开始逐步计算出每个阶段的状态,直到达到最终阶段。
根据问题的要求,确定最终阶段的最优解。
以求解斐波那契数列为例,来说明动态规划的应用:
问题描述:给定一个正整数 n,求解斐波那契数列的第 n 个数。
算法实现步骤:
定义状态:将问题定义为求解第 n 个斐波那契数,状态可以表示为 f(n)。
定义状态转移方程:根据斐波那契数列的定义,第 n 个数等于前两个数之和,即 f(n) = f(n-1) + f(n-2)。
初始化边界状态:根据斐波那契数列的定义,f(0) = 0,f(1) = 1。
通过状态转移方程递推求解:从 f(2) 开始,根据状态转移方程逐步计算出 f(3)、f(4)、...、f(n)。
返回最终阶段的最优解:返回 f(n)。
使用动态规划算法求解斐波那契数列的代码示例(使用递归方式实现状态转移方程):
python
Copy code
def fibonacci(n):
if n == 0:
return 0
if n == 1:
return 1
dp = [0] * (n + 1) # 创建一个数组用于保存中间状态的结果
dp[0] = 0
dp[1] = 1
for i in range(2, n + 1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]
通过调用 fibonacci(n) 函数,可以得到斐波那契数列的第 n 个数的值。这种动态规划的实现方式具有时间复杂度 O(n),相比于简单递归实现的时间复杂度 O(2^n),效率更高。