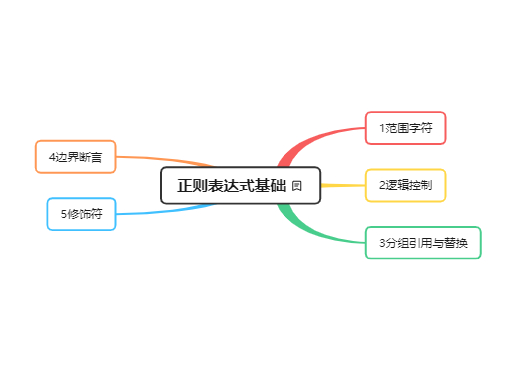
正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于匹配字符串中字符组合的模式。它是一种强大、灵活的文本处理工具,被广泛应用于数据验证、数据提取、文本搜索与替换等场景。
字母和数字:例如 a、A、0 等,它们通常匹配自身。
我们想要查找的字符或单词可以直接输入,就像搜索一样。例如我们要在金山办公WPS正则函数很好用中找到WPS这个词就可以输入同样的内容。
大部分符号:例如 !、@、# 等,它们也通常匹配自身。
?(问号):匹配前面的子表达式零次或一次,
或指明非贪婪搜索。
贪婪模式
非贪婪模式
[]:方括号内的任意一个字符。例如 [wps] 可以匹配 w、p 或 s。
[^]:否定字符集,匹配不在方括号内的任意一个字符。例如 [^wps] 匹配除了w、p、s 之外的。
\:在正则表达式中,转义符号\用于改变紧跟在它后面的字符的字面意义,或者赋予它特殊的意义。
匹配特殊字符:在正则表达式中,某些字符具有特殊含义,如点号 .、星号 *、问号 ? 等。如果你想匹配这些字符本身,需要在它们前面加上转义符号。例如,要匹配字符串中的点号,可以使用 \.。
匹配控制字符:转义符号也可以用来匹配控制字符,如换行符\n、制表符 \t、回车符 \r 等。
匹配元字符:如果你想匹配正则表达式中的元字符,如方括号 []、圆括号 ()、大括号 {} 等,需要在它们前面加上转义符号。例如,要匹配字符串中的左括号,可以使用 \(。
\d:匹配一个数字字符。等价于 [0-9]。
\D:匹配一个非数字字符。等价于 [^0-9]。
\w:匹配包括下划线的任何单词字符。等价于 [A-Za-z0-9_]。
\W:匹配任何非单词字符。等价于 [^A-Za-z0-9_]。
\s:匹配任何空白字符,包括空格、制表符、换行符等等。
|(竖线):或。匹配符号左边的子表达式或右边的子表达式。
():标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
\n:其中 n 是一个正整数,引用第 n 个分组匹配的文本。
零宽断言是正则表达式中的一种特殊构造,用于指定匹配必须发生的位置,但它本身并不消耗任何字符,也就是说,它不会使正则表达式引擎在字符串中向前移动。零宽断言用于限制匹配的上下文,而不影响匹配的结果。
正向先行断言:x(?=y)这意味着x后面必须紧跟y,但y不会被包括在匹配结果中。
匹配任何后面紧跟一个百分号的数字
负向先行断言:x(?!y)这意味着x后面不能紧跟y。
匹配后面不紧跟百分号的数字
正向后发断言:(?<=y)x这意味着x前面必须是y,但y不会被包括在匹配结果中。
匹配任何前面有百分号的数字
匹配前面没有百分号的数字