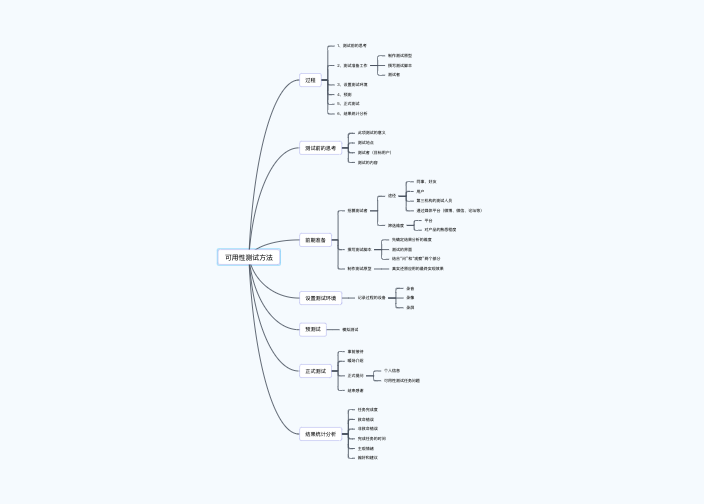
DeepSeek(深度求索)的实现原理融合了多种前沿人工智能技术,其核心设计围绕 “效率优先” 展开,通过架构创新、训练优化与推理加速三大支柱,实现了高性能、低成本、强泛化能力的模型系统。以下从关键技术原理角度详细解析:
DeepSeek 基于 Transformer 架构 进行深度改造,融合了稀疏激活、动态路由、多模态融合等机制:
· 动态路由机制:模型包含大量“专家模块”(如 256 个路由专家 + 1 个共享专家),每个输入 token 仅激活其中一小部分(如 8 个),避免了全参数计算的资源浪费。
· 负载均衡策略:采用 动态偏置调节 与 序列级补偿机制,避免专家负载不均,提升训练稳定性与性能。
· 效果:在同等算力下,模型有效参数利用率提升 10 倍以上,推理成本大幅降低。
· KV 缓存压缩:通过低秩联合压缩技术,将注意力键值对(Key-Value)的存储维度压缩至 512,显存占用减少 70%。
· 查询解耦设计:位置编码(如 RoPE)仅作用于查询分支,避免冗余计算,提升长文本处理效率(支持 128K 上下文)。
· 不同于传统对齐式架构(如 CLIP),DeepSeek 提出 因果感知跨模态融合技术,构建视觉-语言联合因果图,避免伪相关性干扰(如误导性图片配文),在医疗影像诊断等任务中准确率提升 15%。
· 强化学习驱动合成(DSE):使用自博弈机制生成高质量合成数据(如科学推导、代码逻辑),通过 AI 反馈(RLAIF)迭代优化,数据规模年增速达 300%。
· 多令牌预测(MTP):训练时同时预测多个未来 token,增强生成连贯性,推理速度提升 1.8 倍。
· DualPipe 并行架构:结合张量并行、流水线并行与专家并行(如 64 路专家并行),通过计算-通信重叠技术,将流水线气泡时间从 35% 降至 12%,训练吞吐量提升 83%。
· FP8 混合精度训练:前向传播用 FP8 降低计算负载,反向传播切换至 FP16 保持梯度稳定,配合动态指数对齐技术,训练速度达 FP16 的 1.83 倍,内存占用减少 37%。
· 采用“超算中心 + 边缘算力池”混合架构,结合国产芯片(如昇腾)与闲置 GPU 聚合技术,训练成本较行业降低 38%
· 渐进式分层蒸馏:从大模型(如 70B)蒸馏出轻量化子模型(如 33B 的 DeepSeek-R1),保留 95% 性能的同时,推理速度提升 2.3 倍。
· 细粒度量化:支持 FP8/INT4 量化,在 8GB 显存设备(如 M3 Ultra)上流畅运行。
· 结合 MTP 模块实现 推测解码:首先生成草稿序列,再并行验证,加速生成过程。
· 节点受限路由:限制每个 token 最多分布在 4 个物理节点,减少跨节点通信开销。
DeepSeek-R1 通过 纯强化学习框架 实现“顿悟式”能力跃迁:
· 自博弈机制:模型在虚拟环境中通过奖励函数(如答案准确性、格式规范性)自主优化策略,减少人工标注依赖。
· 奖励塑造技巧:针对数学与代码任务设计结构化奖励(如规则验证器、测试用例),在 AIME 数学竞赛中准确率从 15.6% 跃升至 86.7%。
· 全栈开源策略:模型权重(如 DeepSeek-R1)、训练代码、轻量化推理库(FlashMLA)全部开源,吸引全球开发者贡献优化。
· 低成本应用落地:API 定价仅为 GPT-4 的 1/10,支持中小企业在编程、金融、教育等场景快速集成。
技术方向 关键技术 效果
架构创新 MoE + MLA + 因果建模 显存降 70%,长文本连贯性 >94%
训练优化 DualPipe + FP8 + URLF 成本降 90%,训练速度升 1.8×
推理加速 蒸馏 + 量化 + 推测解码 轻量化模型推理速度升 2.3×
开源生态 全栈开源 + 社区协作 衍生 200+ 垂直模型,降低应用门槛
DeepSeek 的核心理念是:以算法创新替代算力堆砌,通过稀疏激活、动态路由、强化学习自进化等机制,在有限资源下实现接近人类水平的认知与推理能力。这一技术路线不仅推动了 AGI 的高效发展,也为全球 AI 开源生态提供了“中国方案”。