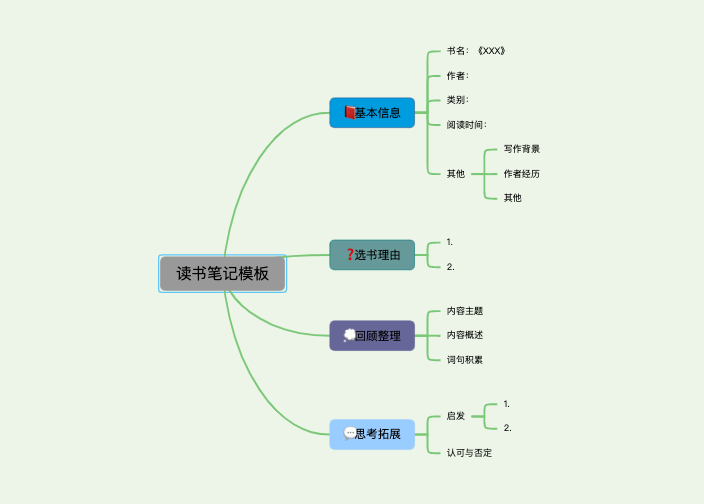
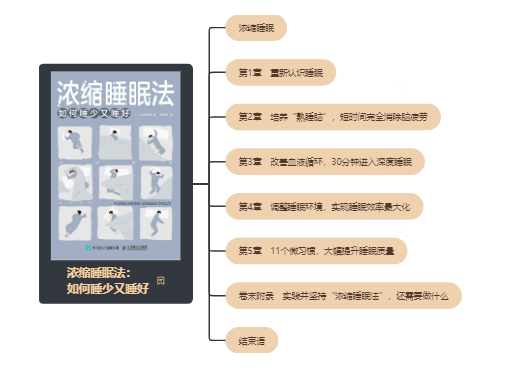
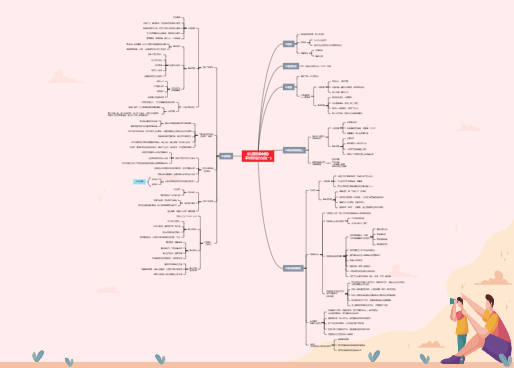
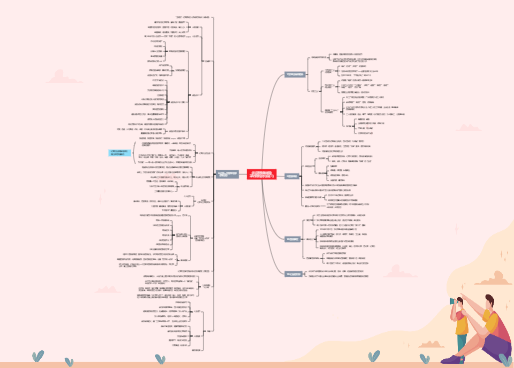
本书下载地址
可用Navicat工具练习,工具下载地址
例如一个文件夹,根据文件名称不同存储多个文件,一个Excel文件根据某种方式归类分为多个表...
数据库软件 有各种不同的数据库,例如MySQL、SqlServer...
也可不用软件,直接用命令创建操作数据库(严格来说还是用了操作系统这种软件)
例如顾客清单、产品清单...
关键一点在于,存储在表中的数据是同一种类型的数据或清单。 决不应该将顾客清单与订单清单存在同一个数据库表中,否则以后检索和访问会很困难。应创建两个表,每个清单一个表。
例如往文件柜中放资料,先在文件柜中创建文件,再把资料放入文件 在数据库中,这种文件被称为表。往数据库中存数据,也需要先建一个表
数据库中的每个表都有一个名字来标识自己,这个名字是唯一的 同一个数据库中,表名称需要是唯一的
关于数据库和表的布局及特性的信息
表具有一些特性,这些特性定义了数据在表中如何存储, 包含存储什么样的数据、数据如何分解、各部分信息如何命名等 描述表的这组信息就是所谓的模式,模式可用来描述数据库中特定的表,也可用来描述整个数据库(和其中表的关系)。
表中的一个字段。所有表都是由一个或多个列组成的。列存储表中某部分的信息。 就像Excel表那样,表中每一列存储着某种特定的数据。
正确地将数据分解为多个列极为重要。通过分解这些数据,才有可能利用特定的列对数据进行分类和过滤 可根据自己的具体需求来决定把数据分解到何种程度
数据库中每个列都有相应的数据类型。数据类型定义了列可存储哪些数据种类。 例如,如果列中存储的是数字(或许是订单中的物品数),则相应的数据类型应该为数值类型。
所允许的数据的类型。每个表列都有相应的数据类型,它限制(或允许)该列中存储的数据。
帮助正确地分类数据,并在优化磁盘使用方面起重要作用。
数据类型及其名称是 SQL不兼容的一个主要原因。在创建表结构时要记住这些差异
表中的一个记录。
表中的数据是按行存储的,所保存的每个记录存储在自己的行内。 就像Excel表那样,垂直的列为表列,水平的行为表行
例如,顾客表可以用顾客编号,而订单表可以用订单 ID。
其值能唯一标识表中每一行的一列(或一组列),这个列(或这几列)称为主键。
没有主键时,更新或删除表中特定行就极为困难,因为你不能保证操作只涉及相关的行。
应该总是定义主键(虽然并不总是需要主键),以便于以后的数据操作和管理。
任意两行都不具有相同的主键值;
每一行都必须具有一个主键值(主键列不允许 NULL 值);
主键列中的值不允许修改或更新
主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
SQL(发音为字母 S-Q-L或 sequel)是 Structured Query Language(结构化查询语言)的缩写
设计SQL的目的是为了很好地完成一项任务---提供一种从数据库中读写数据的简单有效方法
SQL不是某个特定数据库供应商专有的语言。几乎所有重要的 DBMS都支持 SQL
SQL简单易学。它的语句全是由有很强描述性的英语单词组成,且这些单词的数目不多。
SQL虽然看上去很简单,但实际上是一种强有力的语言,灵活使用其语言元素,可以进行非常复杂和高级的数据库操作。
许多DBMS厂商通过增加语句或指令,对 SQL 进行了扩展。 目的是提供执行特定操作的额外功能或简化方法
标准SQL由 ANSI标准委员会管理,称为 ANSI SQL。 所有主要的 DBMS,即使有自己的扩展,也都支持 ANSI SQL。各个实现有自己的名称,如 PL/SQL、Transact-SQL 等。
本书讲授的 SQL 主要是 ANSI SQL。
附录A给了具体样例表,并介绍了获得(或创建)它们的详细步骤
附录B介绍在各种应用程序中执行SQL所需的步骤。
介绍了什么是 SQL,它为什么很有用。因为 SQL是用来与数据库打交道的,所以,也复习了一些基本的数据库术语。
作为 SQL组成部分的保留字,关键字不能做表/列名。
SQL语句由简单的英语单词构成,每个 SQL语句中都有一个或多个关键字
最常使用的SQL语句大概就是SELECT语句了,它的用途是从一个或多个表中检索数据。
为了用SELECT检索表数据,至少要给出两条信息--想选择什么、从什么地方选择。
要理解SQL是一种语言而不是一个应用程序。具体如何写SQL并显示输出,是随不同的应用程序而变化的。
简单的SELECT语句: 用 SELECT 语句从 Products 表中检索一个名为 prod_name的列
所需的列名写在 SELECT 关键字之后, FROM 关键字指出从哪个表中检索数据。
执行后此SQL语句后显示输出结果,将返回表中prod_name列下的所有行。数据没有过滤,也没有排序。(SQL语句里没加过滤/排序等条件,只是简单查询)
如未明确排序查询结果,则返回的数据没有特定的顺序。返回数据的顺序可能是数据被添加到表中的顺序,也可能不是。只要返回相同数目的行,就是正常的。
多条SQL语句必须以分号(;)分隔。
多数DBMS不需要在单条SQL语句后加分号,但也有 DBMS可能必须在单条SQL语句后加上分号。当然,如果愿意可总是加上分号。事实上,即使不一定需要,加上分号也肯定没有坏处。
SQL语句不区分大小写,因此 SELECT 与 select 是相同的。同样,写成 Select 也没有关系。
许多人喜欢对SQL关键字用大写,对列名和表名用小写,这样做使代码更易于阅读和调试。
在处理 SQL语句时,其中所有空格都被忽略。SQL语句可以写成长长的一行,也可以分写在多行。
SELECT prod_name FROM Products;
SELECT prod_name
SELECT
想从一个表中检索多个列,仍然用相同的SELECT语句。唯一不同是须在SELECT关键字后给出多个列名,列名之间以逗号分隔。
在选择多个列时,一定要在列名之间加逗号,但最后一个列名后不加。如在最后一个列名后加了逗号,将报错。
SELECT prod_id, prod_name, prod_price 从Products表中检索prod_id, prod_name, prod_price这三列下的所有行
指定了3个列名,列名间用逗号分隔。
SQL语句一般返回原始的、无格式的数据。数据的格式化是表示问题,而不是检索问题。
给定一个通配符( * ),则返回表中所有列。
列的顺序一般是列在表定义中出现的物理顺序,但并不总是如此。
除非你确实需要表中的每一列,否则最好别使用 * 通配符。
由于不明确指定列名(因为星号检索每一列),所以能检索出名字未知的列。
SELECT DISTINCT vend_id DISTINCT告诉DBMS从Products表中检索后只返回不同的(具有唯一性)vend_id 行(过滤vend_id重复的行,只显示其中的一个,其它的重复行不显示)
如使用 DISTINCT 关键字,它必须直接放在列名的前面
DISTINCT 关键字作用于所有的列,不仅仅是跟在其后的那一列。
返回结果时,不想要所有行,只想返回第一行或指定数量的行,可限制返回结果
在SQL Server和 Access中用SELECT,可用TOP关键字来限制最多返回多少行 SELECT TOP 5 prod_name 只检索前 5行数据
SELECT prod_name FROM Products FETCH FIRST 5 ROWS ONLY;
MySQL、MariaDB、PostgreSQL或SQLite, SELECT prod_name FROM Products LIMIT 5 指返回不超过 5行数据
SELECT prod_name FROM Products LIMIT 5 OFFSET 4 指返回从第 4行起的 5行数据
OFFSET 指定从哪儿开始
第一个被检索的行是第 0行,而不是第 1行。按索引下标来检索。
MySQL和MariaDB支持简化版的 LIMIT 5 OFFSET 4 语句,即 LIMIT 4,5 。
SELECT prod_name FROM Products; -- 这是一条单行注释,添加一些描述性的内容 使用 -- (两个连字符)嵌在行内, -- 之后的文本就是注释
# 这是一条注释 这种形式很少得到支持
/*注释掉无需执行的某些SQL代码 注释从 /* 开始,到 */ 结束。 /* 和 */ 之间的任何内容都是注释。
学习了如何使用 SQL的 SELECT 语句来检索单个表列、多个表列以及所有表列。也学习了如何返回不同的值,如何注释代码。
检索时如不排序,检索出的数据一般以它在底层表中出现的顺序显示,这有可能是数据最初添加到表中的顺序。 如果数据随后进行过更新或删除,顺序将受DBMS重用回收存储空间方式的影响。
关系数据库设计理论认为‘如果不明确规定排序顺序,则不应该假定检索出数据的顺序有任何意义。’
SQL语句由子句clause构成,有些子句是必需的,有些是可选的。一个子句通常由一个关键字加所提供的数据组成。
ORDER BY子句取一个或多个列的名字,据此对输出进行排序。
SELECT prod_name FROM Products ORDER BY指示DBMS软件对prod_name列排序(字符串会按字母顺序排序)
在指定一条ORDER BY子句时,应保证它是SELECT语句中最后一条子句,否则会报错。
通常,ORDER BY子句中使用的列是为显示而选的列。但实际并不一定要这样,用非检索的列排序数据是完全合法的。
指定列名,列名之间用逗号分隔即可按多个列排序。
SELECT prod_id, prod_price, prod_name FROM Products 按多个列排序,列名之间使用逗号分隔
1.先对prod_price进行排序;
SELECT prod_id, prod_price, prod_name FROM Products SELECT清单中指定选择列的相对位置而不是列名。ORDER BY 2表示按SELECT清单中的第二个列prod_name进行排序。
好处在于不用重新输入列名。但也有缺点。
数据排序不限于升序(从 A到 Z),这只是默认的排序顺序。还可用ORDER BY子句进行降序(从 Z 到 A)。为了进行降序排序,须指定用DESC关键字。
SELECT prod_id, prod_price, prod_name FROM Products 以prod_price降序来排序产品(最贵的排在最前面)
SELECT prod_id, prod_price, prod_name FROM Products 只对prod_price列指定DESC降序,对 prod_name 列不指定。因此prod_price列以降序排序,而prod_name列仍按标准的升序排序。
DESC只作用于其前面的一个列名。如想在多个列上进行降序排序,须对每一列指定DESC关键字。
DESC是DESCENDING的缩写,这两个关键字都可以使用。与 DESC 实际上,ASC没多大用处,因为升序ASC是默认的(如果既不指定ASC,也不指定DESC ,则假定为ASC)。
学习了如何用SELECT语句的ORDER BY子句对检索出的数据进行排序。这个子句必须是SELECT语句中的最后一条子句。根据需要,可利用它在一个或多个列上对数据进行排序。
数据库包含大量数据,通常只检索指定搜索条件(search criteria)的数据,搜索条件也称为过滤条件(filter condition)。
SELECT 语句中,数据根据WHERE子句中指定的搜索条件进行过滤,WHERE子句在表名(FROM子句)之后给出。
SELECT prod_name, prod_price FROM Products 从products表中检索两个列,但不返回所有行,只返回prod_price值等于3的数据。
数据可在应用层过滤。为此,SELECT语句为客户端应用检索出超过实际所需的数据,然后客户端代码对返回数据进行循环,提取出需要的行。
通常,这种做法不妥。优化数据库后可更快速有效地对数据进行过滤。
操作符及说明:
--检索过滤prod_price 小于 10的数据
--检索过滤vend_id 不等于DLL01的数据 != 和 <> 可互换。并非所有DBMS都支持这两种不等于操作符。如Microsoft Access支持<>,而不支持 != 。MySQL支持!=。
单引号用来限定字符串。如果将值与字符串类型的列进行比较,就要限定引号。与数值列进行比较不用引号。
--检索过滤prod_price在5和10之间的值(包含5和10) 在用BETWEEN检查某个范围的值时,须指定两个值-所需范围的开始值和结束值。这两个值必须用AND关键字分隔。
BETWEEN匹配范围中所有的值,包括指定的开始值和结束值。
SELECT prod_name FROM Products 一个列不包含值时,称其包含空值/无值NULL(no value),NULL值与字段包含0、空字符串或仅仅包含空格不同。
确定值是否为 NULL,不能简单地检查是否 = NULL。SELECT语句有一个特殊的WHERE子句‘IS NULL 子句’,可用来检查具有NULL值的列。
返回所有没有价格(空prod_price字段,不是价格为0)的prod_name数据
过滤选择不包含指定值的行时,可能希望返回含NULL值的行。但这做不到。因为未知(unknown)有特殊的含义,数据库不知道它们是否匹配,所以在进行匹配过滤或非匹配过滤时,不会返回这些结果。过滤数据时,一定要验证被过滤列中含NULL的行确实出现在返回的数据中。
介绍了如何用SELECT语句的WHERE 子句过滤返回的数据。学习了如何检验相等、不相等、大于、小于、值的范围以及 NULL值等。
为了进行更强的过滤控制,SQL允许给出多个WHERE子句。这些子句有两种使用方式,即以AND子句或OR子句的方式使用。
操作符(operator)用来联结或改变WHERE子句中的子句的关键字,也称为逻辑操作符(logical operator)。 要通过不止一个列进行过滤,可以使用AND或OR操作符给WHERE子句附加条件。
--AND 这条SELECT语句中的WHERE子句包含两个条件,用AND关键字联结在一起。
AND用在WHERE子句中,用来指示检索满足所有给定条件的行,指示DBMS只返回满足给定条件的行。
如某个产品由供应商DLL01制造,但价格高于 4美元,则不检索它。
可以再增加多个过滤条件,每个条件间要使用AND关键字。
--OR OR操作符与AND操作符正好相反,它指示DBMS检索匹配任一条件的行。事实上,许多DBMS在OR第一个条件得到满足的情况下,就不再计算第二个条件了(在第一个条件满足时,不管第二个条件是否满足,相应的行都将被检索出来)。
检索由任一个指定供应商制造的所有产品的产品名和价格。OR 操作符告诉 DBMS匹配任一条件而不是同时匹配两个条件。如果这里使用的是 AND 操作符,则没有数据返回(因为会创建没有匹配行的 WHERE子句)。
SELECT prod_name, prod_priceFROM Products 可包含任意数目的AND和OR操作符。允许两者结合进行复杂、高级的过滤。
SQL(像多数语言一样)在处理 OR 操作符前,优先处理AND操作符。
此SQL理解为:由供应商BRS01制造的价格为10美元以上的所有产品,以及由供应商 DLL01 制造的所有产品,而不管其价格如何。
SELECT prod_name, prod_price FROM Products 语句将前两个条件用圆括号括了起来。因为圆括号具有比AND或OR操作符更高的求值顺序,所以DBMS先过滤圆括号内的OR条件。
此SQL理解为:选择由供应商 DLL01或 BRS01制造的且价格在10美元及以上的所有产品。
任何时候使用具有AND和OR操作符的WHERE子句,都应使用圆括号明确地分组操作符。不要过分依赖默认求值顺序。使用圆括号没有什么坏处,它能消除歧义。
IN操作符用来指定条件范围,范围中的每个条件都可进行匹配。IN取一组由逗号分隔、括在圆括号中的合法值。功能与 OR 相当。
SELECT prod_name, prod_price FROM Products 检索由供应商DLL01和BRS01制造的所有产品。IN操作符后跟由逗号分隔的合法值,这些值必须括在圆括号中。
在有很多合法选项时, IN 操作符的语法更清楚,更直观。
NOT操作符有且只有一个功能,那就是否定其后所跟的任何条件。因为NOT从不单独使用(它总是与其他操作符一起使用),所以它的语法与其他操作符有所不同。 NOT 关键字可以用在要过滤的列前,而不仅是在其后。
SELECT prod_name FROM Products 这里的NOT否定跟在其后的条件,因此,DBMS不是匹配vend_id为DLL01 ,而是匹配非DLL01之外的所有行。
也可以使用 <> 操作符来完成
在更复杂的子句中, NOT是非常有用的。 SELECT prod_name FROM Products
讲授如何用AND和OR操作符组合成WHERE 子句,还讲授了如何明确地管理求值顺序,如何使用IN和NOT操作符。
怎样搜索产品名中包含文本bean bag的所有产品? 通配符(wildcard):用来匹配值的一部分的特殊字符
通配符搜索只能用于文本字段(字符串),非文本数据类型不能使用通配符搜索。
通配符实际上是SQL的WHERE子句中有特殊含义的字符,SQL支持几种通配符。
搜索模式(search pattern):由字面值、通配符或两者组合构成的搜索条件。
操作符何时不是操作符?
为在搜索子句中使用通配符,须使用LIKE操作符。 LIKE指示DBMS,后跟的搜索模式利用通配符匹配而不是简单的相等匹配进行比较。
SELECT prod_id, prod_name FROM Products 最常使用的通配符是百分号(%)。在搜索串中,%表示任何字符出现任意次数。
搜索模式'Fish%',执行时,将检索任意以Fish起头的词。%告诉DBMS接受Fish之后的任意字符,不管它有多少字符。
如果使用Microsoft Access,需使用 * 而不是 % 。
根据DBMS的不同及其配置,搜索可以区分大小写。如果区分大小写,则'fish%'与'Fish bean bag toy'就不匹配。
SELECT prod_id, prod_name FROM Products 通配符可在搜索模式中的任意位置使用,且可使用多个通配符。
搜索模式'%bean bag%'表示匹配任何位置上包含文本bean bag的值,不论它之前或之后出现什么字符。
SELECT prod_name FROM Products 有一种情况很有用,就是根据邮件地址的一部分查邮件,如WHERE email LIKE'b%@forta.com' 。
除了能匹配一个或多个字符外,%还能匹配0个字符。%代表搜索模式中给定位置的0个、1个或多个字符。
包括Access在内的许多DBMS都用空格来填补字段的内容。
例如,如果某列有50个字符,而存储的文本为Fish bean bag toy(17个字符),为填满该列需在文本后附加33个空格。这样做一般对数据及其使用没影响,但可能对SQL语句有负面影响。子句WHER Eprod_name LIKE'F%y'只匹配以F开头、以y结尾的prod_name 。如果值后面跟空格,则不是以y结尾,是以空格结尾,所以 Fish bean bag toy 就不会检索出来。简单的办法是给搜索模式再增加一个%号:'F%y%',匹配y之后的字符(或空格)。更好的解决办法是用函数去掉空格。
通配符%看起来像可以匹配任何东西,但有个例外,就是NULL 。子句WHERE prod_name LIKE '%' 不会匹配产品名称为NULL的行。
下划线的用途与%一样,但它只匹单个字符,而不是多个字符。
如果使用的是Microsoft Access,需要使用?而不是 _ 。
SELECT prod_id, prod_name FROM Products 此WHERE子句中的搜索模式给出了后面跟有文本的两个通配符‘__’。结果只显示匹配搜索模式的行:第一行中下划线匹配12,第二行中匹配18。8 inch teddy bear 产品没有匹配,因为搜索模式要求匹配两个通配符而不是一个。
与%能匹配0个字符不同, _ 总是只匹配一个字符,不能多也不能少。
方括号([])通配符用来指定一个字符集,它必须匹配指定位置(通配符的位置)的一个字符。 并不总是支持集合与前面描述的通配符不一样,并不是所有 DBMS都支持用来创建集合的 [] 。只有微软的 Access 和 SQL Server 支持集合。为确定你用的DBMS是否支持集合,请参阅相应文档。
SELECT cust_contact FROM Customers 此语句的WHERE子句中的模式为 '[JM]%' 。这一搜索模式使用了两个不同的通配符。[JM]匹配方括号中任意一个字符,它也只能匹配单个字符。因此,任何多于一个字符的名字都不匹配。 [JM] 之后的%通配符匹配第一个字符之后的任意数目的字符,返回所需结果。
此通配符可用前缀字符 ^ ^ (脱字号)来否定。
SELECT cust_contact FROM Customers Access中的否定集合,如果使用的是Microsoft Access,需要用 ! 而不是 ^ 来否定一个集合,因此,使用的是 [!JM] 而不是 [ ^ JM] 。
SELECT cust_contact FROM Customers 也可用 NOT 操作符得出类似的结果。^ 的唯一优点是在使用多个 WHERE 子句时可简化语法:
通配符搜索一般比前面讨论的其他搜索要耗费更长的处理时间 1.不要过度使用通配符。如果其他操作符能达到相同目的,应使用其他操作符;
介绍了什么是通配符,如何在WHERE子句中使用SQL通配符,还说明了通配符应该细心使用,不要使用过度。
为什么需要计算字段?
什么是计算字段?
字段(field),基本上与列(column)的意思相同,经常互换使用,不过数据库列一般称为列,而术语字段通常与计算字段一起使用。
要注意,只有数据库知道SELECT语句中哪些列是实际的表列,哪些列是计算字段。
客户端与服务器的格式:
将值联结到一起(将一个值附加到另一个值)构成一个新的单个值。
在SELECT语句中,可用一个特殊的操作符来拼接两个列。根据你所使的DBMS,此操作符可用加号(+)或两个竖杠(||)表示。
Access和SQL Server使用 + 号
DB2、Oracle、PostgreSQL、SQLite和Open Office Base 使用 || 。
MySQL、MariaDB中,须用特殊的函数。
SELECT vend_name + '(' + vend_country + ')' FROM Vendors 从vendors表检索vend_name和vend_country,用+拼接这两列,再多拼接个括号,把vend_country的数据放在括号中,最后再按vend_name排序。
输出结果,例如:Bear Emporium(USA)
SELECT vend_name || ' (' || vend_country || ')' FROM Vendors 用法同上,只不过使用了 || 拼接符号
SELECT Concat(vend_name, '(', vend_country, ')') FROM Vendors MySQL、MariaDB时需要使用的语句
此语句用Concat( )函数拼接以下元素,元素间用逗号分隔,并返回包含这些元素的一个列(计算字段):
输出结果,例如:Bear Emporium(USA)
看看上述SELECT语句返回的输出,结合成一个计算字段的两个列用空格填充。许多数据库(不是所有)保存填充为列宽的文本值,而实际你要的结果不需要这些空格。为正确返回格式化的数据,须去掉这些空格,可用SQL的TRIM() 函数来完成。
SELECT TRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' FROM Vendors RTRIM( ) 它去掉字符串右边的空格,
SELECT语句可很好地拼接地址字段。但是,这个新计算列的名字是什么呢?实际上它没有名字,它只是一个值。如果仅在 SQL查询工具中查看一下结果,这样没有什么不好。但是,一个未命名的列不能用于客户端应用中,因为客户端没办法引用它。为了解决这问题,SQL 支持列别名。
别名是一个字段或值的替换名
在很多DBMS中,AS关键字是可选的,不过最好使用它,这被视为一条最佳实践。
别名还有其他用途。常见用途包括在实际的表列名包含不合法的字符(如空格)时重新命名它,在原来的名字含混或容易误解时扩充它。
别名的名字既可以是一个单词,也可以是一个字符串。如果是字符串,字符串应括在引号中。虽然这种做法是合法的,但不建议这么做。多单词的名字可读性高,不过会给客户端应用带来各种问题。因此,别名最常见的使用是将多个单词的列名重命名为一个单词的名字。
别名有时也称为导出列(derived column),不管怎么叫,它们所代表的是相同的东西。
SELECT Concat(vend_name, ' (', vend_country, ')') AS vend_title SELECT语句本身与以前的使用相同,只是这里的计算字段后跟了AS vend_title。它指示SQL创建一个包含指定计算结果的名为vend_title的计算字段。从输出可看到,结果与以前相同,但现在列名vend_title,任何客户端应用都可按名称引用这个列,就像它是一个实际的表列一样。
SELECT TRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' AS vend_title
SELECT prod_id, quantity, item_price FROM OrderItems 从表OrderItems中检索 过滤order_num = 20008 的各字段
SELECT prod_id, quantity, item_price, quantity * item_price AS expanded_price SQL中用AS起别名,输出中显示的 expanded_price 起别名的列是一个计算字段,此计算为 quantity*item_price 。客户端应用现在可以使用这个新计算列,就像使用其他列一样。
可用圆括号来区分优先顺序
SELECT语句为测试、检验函数和计算提供了很好的方法。虽然SELECT通常用于从表中检索数据,但是省略了FROM子句后就是简单地访问和处理表达式,
介绍了计算字段以及如何创建计算字段。用例子说明了计算字段在字符串拼接和算术计算中的用途。此外,还讲述了如何创建和使用别名,以便应用程序能引用计算字段。
函数一般是在数据上执行的,为数据的转换和处理提供了方便。例如上一课的TRIM( )就是一个去掉字符串首尾空格的函数。
每个DBMS都有特定的函数。事实上,只有几个函数被所有主要的DBMS等同地支持。虽然所有类型的函数一般都可在每个DBMS中使用,但各个函数的名称和语法可能极其不同。
Access、Oracle使用多个函数,每种类型的转换有一个函数;
Access用 MID( );
Access 用 NOW( ) ;
所编写的代码可以在多个系统上运行
SQL函数不是可移植的,这意味着为特定SQL实现编写的代码在其他实现中可能不正常。
为了代码的可移植,许多程序员不赞成使用特定于实现的功能。虽然这样做很有好处,但有时候并不利于应用程序的性能。如果不使用这些函数,编写某些应用程序代码会很难。必须用其他方法来实现DBMS可以完成工作。
是否该用函数?
1.用于处理文本字符串(如删除或填充值,转换值为大写或小写)的文本函数。
UPPER( ) --vend_name都列出两次,第一次为 Vendors 表中存储的值,第二次作为列 vend_name_upcase 转换为大写。
LOWER( ) 将字符串转换为小写 --从表Vendors检索,第一列为表中存储的值,第二列为转换为小写的列值,排序用默认asc升序。
LEFT( ) (或使用子字符串函数) 返回字符串左边的字符
RIGHT( ) (或使用子字符串函数) 返回字符串右边的字符
LENGTH( ) (也使用 DATALENGTH() 或 LEN() ) 返回字符串的长度
LTRIM( ) 去掉字符串左边的空格
RTRIM( ) 去掉字符串右边的空格
SOUNDEX( ) 返回字符串的SOUNDEX值 SOUNDEX是将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对字符串进行发音比较而不是字母比较。虽然SOUNDEX不是 SQL 概念,但多数DBMS都提供对SOUNDEX的支持。
如在创建SQLite时使用了SQLITE_SOUNDEX编译时选项,那么SOUNDEX( )在 SQLite 中就可用。因为SQLITE_SOUNDEX不是默认的编译时选项,所以多数SQLite实现不支持 SOUNDEX( )。
SELECT cust_name, cust_contact FROM Customers 此语句只能精确过滤cust_contact的值
SELECT cust_name, cust_contact FROM Customers 使用SOUNDEX( )函数把cust_contact列值和搜索字符串转换为它们的SOUNDEX值。因为Michael Green和Michelle Green发音相似,所以它们的 SOUNDEX值匹配,因此WHERE子句正确地过滤出了所需数据。
日期和时间采用相应的数据类型存储在表中,每种DBMS都有自己的特殊形式。日期和时间值以特殊的格式存储,能快速有效的排序或过滤,且节省物理存储空间。
应用程序一般不用日期和时间的存储格式,因此日期和时间函数总是用来读取、统计和处理这些值。由于这个原因,日期和时间函数在 SQL中具有重要的作用。遗憾的是,它们很不一致,可移植性最差。
SELECT order_num FROM Orders SQL Server适用
SELECT order_num FROM Orders SQL Server和Sybase版本以及Access版本适用
DATEPART( )此函数返回日期的某一部分。此函数有两个参数,它们分别是返回的成分和从中返回成分的日期。此例中,DATEPART( )只从order_date列中返回年份。通过与2012比较,WHERE子句只过滤出年份=2012的订单。
SELECT order_num FROM Orders PostgreSQL适用
SELECT order_num FROM Orders Oracle适用
to_char( )用来提取日期的成分,
SELECT order_num FROM Orders 此例中,Oracle的to_date( )函数将两个字符串转换为日期。
注意,相同的代码在SQL Server中不起作用,因为它不支持to_date( )函数。但是,如果用CONVERT( )替换to_date( ),当然可以使用这种类型的语句。
SELECT order_num FROM Orders MySQL、MariaDB可用YEAR( )函数从日期中提取年份
SELECT order_num FROM Orders SQLite中有个技巧:这里给出的例子提取和使用日期的成分(年)。按月份过滤,可进行相同的处理,使用AND操作符可以进行年和月份的比较。
DBMS提供的功能远不止简单的日期成分提取。多数DBMS有比较日期、执行基于日期的运算、选择日期格式等函数。但可看到,不同DBMS的日期、时间处理函数可能不同,可参阅相应的文档。
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角或几何运算,因此不像字符串或日期、时间处理函数使用那么频繁。在主要 DBMS的函数中,数值函数是最一致、最统一的函数。
SELECT order_price, ABS(order_price) FROM Orders
COS( ) 返回一个角度的余弦
EXP( ) 返回一个数的指数值
PI( ) 返回圆周率
SIN( ) 返回一个角度的正弦
SQRT( ) 返回一个数的平方根
TAN( ) 返回一个角度的正切
介绍了如何用SQL的函数。虽然这些函数在格式化、处理和过滤数据中非常有用,但它们在各种SQL实现中很不一致。
1.确定表中行数(或所有行或满足某个条件或包含某个特定值);
对某些行运行的函数,计算并返回一个值。
聚集函数在各主要SQL实现中得到了相当一致的支持
利用COUNT( )确定表中行的数目或符合特定条件的行的数目
用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
用COUNT(column) 对特定列中具有值的行进行计数,忽略 NULL 值。column为指定条件的列值。
SELECT COUNT(*) AS num_cust FROM Customers; 对Customers表中所有行数目计数,并对返回值起别名
SELECT COUNT(cust_email) AS num_cust FROM Customers; 对指定cust_email列的行数计数,并对返回值起别名
如指定列名,则COUNT( )函数会忽略指定列的值为空为null的行。如果COUNT( )函数中用的是星号( * ),则不忽略。
MAX() 返回指定列中的最大值,要求指定列名。
SELECT MAX(prod_price) AS max_price FROM Products; 返回prod_price列中的最大值,并对返回值起别名
虽然 MAX( )一般用来找出最大的数值或日期值,但许多(并非所有)DBMS允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。在用于文本数据时, MAX() 返回按该列排序后的最后一行。
MAX( )函数忽略列值为 NULL 的行
MIN( )的功能与MAX( )功能相反,它返回指定列的最小值。与MAX( )一样,MIN( )要求指定列名。
SELECT MIN(prod_price) AS min_price FROM Products; 返回prod_price列的最小值,并对返回值起别名
虽然MIN( )一般用来找出最小的数值或日期值,但许多(并非所有)DBMS 允许将它用来返回任意列中的最小值,包括返回文本列中的最小值。在用于文本数据时, MIN() 返回该列排序后最前面的行。
MIN( )函数忽略列值为 NULL 的行
通过对表中行数计数并计算其列值之和,求得该列的平均值。 可返回所有列的平均值,也可返回特定列或行的平均值。
SELECT AVG(prod_price) AS avg_price FROM Products; 返回指定列的平均值,并给返回值起别名
SELECT AVG(prod_price) AS avg_price FROM Products 过滤vend_id条件,返回指定列的平均值,并给返回值起别名
只用于单个列,AVG( )只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个 AVG( ) 函数。
AVG( )函数忽略列值为NULL的行
SUM( )用来返回指定列值的和(总计)
SELECT SUM(quantity) AS items_ordered FROM OrderItems 过滤order_num,并返回列quantity的总计和,并对返回值起别名
SELECT SUM(item_price*quantity) AS total_price FROM OrderItems SUM( )也可以用来合计计算值
过滤order_num,先计算item_price*quantity各行的值,再把值汇总返回总计和,再把总计和起别名
在多个列上进行计算如本例所示,利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。
SUM( )函数忽略列值为 NULL 的行
1.对所有行执行计算,指定ALL参数或不指定参数(因为 ALL 是默认行为)。 ALL参数不需要指定,它是默认行为。如果不指定DISTINCT,则默认为ALL 。
Microsoft Access在聚集函数中不支持DISTINCT。要在Access得到类似结果,需使用子查询把DISTINCT数据返回到外部SELECT COUNT(*) 语句。
SELECT AVG(DISTINCT prod_price) AS avg_price FROM Products 过滤vend_id,取不同的prod_price值,并对其取平均值,再对返回的平均值起别名
如果指定列名,则DISTINCT只能用于COUNT( ) 。DISTINCT不能用于 COUNT(*) 。类似地, DISTINCT 必须使用列名,不能用于计算或表达式。
虽然DISTINCT从技术上可用于MIN() 和 MAX() ,但这实际上没价值。一个列中的最小值和最大值不管是否只考虑不同值,结果都是相同的
目前为止的所有聚集函数例子都只涉及单个函数。实际上, SELECT语句可根据需要包含多个聚集函数。
SELECT 单条语句执行了4个聚集计算,返回4个值(Products表中物品的数目、产品价格的最高值、最低值、平均值)。
在指定别名以包含某个聚集函数的结果时,不应使用表中实际的列名。虽然这样做也合法,但许多SQL实现不支持,可能会产生模糊的错误消息。
聚集函数用来汇总数据。SQL 支持 5 个聚集函数,可以用多种方法使用它们,返回所需的结果。这些函数很高效,它们返回结果一般比你在自己的客户端应用程序中计算要快得多。
目前为止所有计算都是在表的所有数据或匹配特定WHERE子句的数据上进行的。 如果要返回每个供应商提供的产品数目,该怎么办?
使用分组可将数据分为多个逻辑组,对每个组进行聚集计算。
分组使用GROUP BY子句
SELECT vend_id, COUNT(*) AS num_prods FROM Products 指定了两个列,vend_id产品供应商ID,num_prods计算字段(用 COUNT(*) 建立)统计所有行。
GROUP BY指示DBMS按vend_id分组数据,每组vend_id显示计算后的对应num_prods。
GROUP BY可包含任意数目的列,因而可对分组进行嵌套,更细致地进行数据分组。
如在GROUP BY中嵌套了分组,数据将在最后指定的分组上进行汇总。也就是说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
GROUP BY中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如在SELECT中使用表达式,必须在 GROUP BY中指定相同的表达式,不能使用别名。
多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)。
除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
如果分组列中包含有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
GROUP BY必须出现在WHERE之后, ORDER BY之前。
有的SQL实现允许根据SELECT列表中的位置指定GROUP BY的列。
WHERE过滤指定的是行,而不是分组。事实上,WHERE没有分组的概念。
不使用WHERE,使用什么呢? HAVING非常类似WHERE 。事实上,目前为止所学所有类型的WHERE子句都可用HAVING替代。 唯一差别是,WHERE过滤行,HAVING过滤分组。
HAVING支持所有WHERE操作符
SELECT cust_id, COUNT(*) AS orders FROM Orders 指定两列,cust_id,统计所有行并重命名后的列orders。
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。
SELECT vend_id, COUNT(*) AS num_prods FROM Products WHERE过滤所有prod_price大于等于4的行,先过滤一些无效数据不进入分组计算。
1.对产生的输出排序;
1.对行分组,但输出可能不是分组的顺序;
应提供明确的ORDER BY子句,即使其效果等同于GROUP BY子句。 一般在用GROUP BY时,应该也给出ORDER BY。这是保证数据正确排序的唯一方法。不要仅依赖GROUP BY排序数据。
SELECT order_num, COUNT(*) AS items FROM OrderItems 按order_num分组,以便 COUNT(*) 函数能够返回每个订单中的物品数目。
是否必须使用: 是
是否必须使用: 仅在从表选择数据时使用
是否必须使用: 否
是否必须使用: 仅在按组计算聚集时使用
是否必须使用: 否
是否必须使用: 否
讲了如何用GROUP BY对多组数据进行汇总计算,返回每个组的结果。
11.1 子查询
11.2 利用子查询进行过滤
11.3 作为计算字段使用子查询
11.4 小结
第 12 课 联结表
第 13 课 创建高级联结
第 14 课 组合查询
第 15 课 插入数据
第 16 课 更新和删除数据
第 17 课 创建和操纵表
第 18 课 使用视图
第 19 课 使用存储过程
第 20 课 管理事务处理
第 21 课 使用游标
第 22 课 高级 SQL 特性