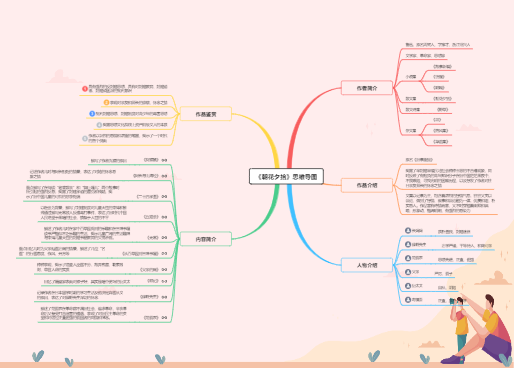
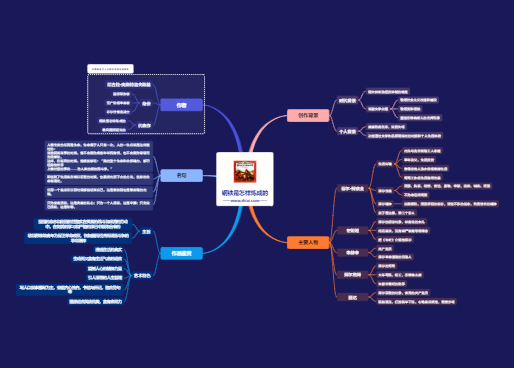
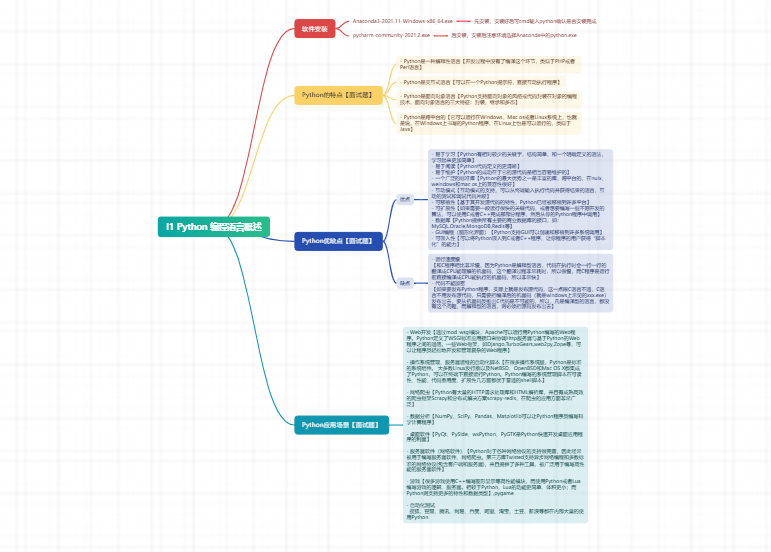
畅销书《python从入门到实践》知识思维导图 lower()
print(kb.rstrip().lstrip())#短暂删除
1,同时打印出多个数
3,保留小数
4,修改分隔符和结束符
1,控制print 的输出格式
2,保留小数 百分数
3,f-string 更快的format 输入法
4,可以参与循环,使得表达式看起来更加清晰直观
1,保留小数 ---四舍五入!
1,查找字符串 ---( "x" in / not in ) 或者 find ( "x" ) type ( a ) ---查看类型
2,字符串的索引切片---切片是闭区间!不含最后一个字符串!
3,字符串的分隔split 、移除strip
同时赋值
列表用这个[ ]表示,在后面加索引确定位置,
列表一般先设置一个空列表,然后再append操作添加,
列表的元素要打印时,一般情况下,得用for循环,逐一打印出来,不能直接打
ways[0]='swim' #可以修改任意位置的元素
合并用 + 或者 extend( 列表 ), 复制用 * ,可以混和不同形式的列表
ways.append('car')
homeways.insert(0,'fly')
del ways[0]#注意格式,del指定位置删除
#方法pop删除元素,并保留元素(与del的区别在于是否继续使用!)
#remove,知道值是多少,但不知道位置在哪,并且删掉后可以再使用(类似pop),如果有多个值,用IF循环来判断删完了么。
#方法一,sort对列表按字母顺序永久排序
临时排序——sorted(列表)
index ()
count ( )
asd = [1, 2, 3, 4, 5]
zip 打包----配对,组成元组,再作为元素计入列表
for value in range(1,5): #实际上是1,2,3,4,没有5,达到5之后停止!
for循环遍历列表每个元素 for i in range(1,10):
friend_fruits=fruits[:]
#使用range()创建数字列表,结合list创建!!!牢记!!!
#列表解析,将for循环和创建新元素的代码合并成一行,并自动附加新元素
同时进行两个解析,注意解析的层次关系
players[0:3]) #当到达3,也就是第四个元素时停止
for player in players[:2]:
for alien in aliens [:5]: #只显示前5个外星人,切片!!!
#修改前3个外星人的数据:
dimensions=(200,50)
检查是否等于、大于小于、不等于!=
#检查多个条件,用and和or来简化运算!!!注意格式!!
#检查特定值是否包含在列表中!和不在列表中——in 和 not in
car='SuBa'
print(cars=='bao ma')
print(10>9)
就是用简单的==来输出true和false这两种结果
if age<4:
学会用多个if,
if + 字符串切片 +print 深度使用
for topping in toppings:
if toppings:
for yuanliao in yuanliao2:
new_yonghus=['jing','hong','cong','Xing','admin']
#字典可以存储一个对象的多种信息,比如外星人的各种信息,但也可以存储众多对象的同一种信息,比如调查很多人最喜欢的编程是什么。
#要访问相关联的值,要依次指定 字典名 + 键!
添加:键值 对
#删除键值对,用del彻底永久删除,但需要指明字典名和要删除的键
#声明2个变量,存储键和值,同时引用字典名.items(),依次储存!
不需要用到值时,遍历所有键
遍历字典中的所有值,用values()
列表里装一个个字典 创建一个外星人列表,其中每个外星人都是一个字典,包含有关该外星人的各种信息。
#下面是多个外星人的自动生成
#字典,要符合键-值,但里面的值也可以是列表! #for循环+字典-键 :不断提取(键)列表里面的值!
#总结,如果需要在字典中将其中的一个键关联到多个值,可以在里面嵌套一个列表!
#这里的格式不统一,容易出错!!!
多个网站,每个网站有多个用户名,作为字典中的键,然后每个用户名下有多个信息,将其存储在字典中,作为与键对应的值!
字典中的值,就是一个字典,再引用的时候,要用引用字典值的方式来用,新设变量来存储: 字典【键】 下的值
不能太多层级,不然可能有更好的解决方法
prompt提示可以放到一个变量里面,再传递(以免太长)
input解读为字符串,数值形式的话要加Int(),但是用float最保险(防止输入小数后报错),或者用eval---去除输入字符串的双引号!!!
求模运算符%,它将两数相除并返回余数(很有用)
#让用户选择何时退出
使用标志:就是让程序判断什么时候结束,标志为true,运行false,停止!有以下几种方法 和下面两种的区别在于,即便标志变量为false了,下面的程序还会继续执行
和上面两个相比,多了一个while下的判断!
while和for循环本质差别在于,while循环是一个有条件的循环,而for循环就是单纯地遍历列表的每个元素
高效处理代码
传递实参
传递实参 的默认值—— def describe_pet (pet_name , pet_type ='dog') :
函数就是自定义形参的用法:
就是要把实参的值,传递到字典的值里面!!!
定义的函数要返回到字典,且字典里面存在默认值
综合
形参为列表,一般都会和for循环遍历 结合起来
运行函数修改代码,修改的效果是永久的! 千万注意:函数括号内不能直接【'a', 'b', 'c'】,不能直接放列表啊,应该把列表先存在变量里,再把这个变量作为实参,放进函数括号内!
精品案例!!!
不改动原列表,进行操作,不是单调的 a = xxx . pop (0)
禁止函数修改列表———运用函数,在调用列表时,用切片法,引用副本 [ : ]
传递任意数量的实参——妙用*号,就是创建一个空元组
什么时候用列表,什么时候用字典,得看情况
使用任意数量的关键字实参 ——精品(注意函数中对空字典的运用)
将函数都放在模块py文件上,要用时再导入主程序,可以简化流程,重点放在代码逻辑上
文件:模块.py ——内含函数make_pizz( )
导入全部,不推荐
给模块 或 函数 改成自定义名---用 as
map 函数, 表现形式为map (function,agrs) ,表示对序列args中的每个值进行function操作,最终得到一个结果序列------ 用 List 转为列表形式
map ( 函数 / ( lambda x,y : x 和 y 的运算) ,列表---对应x 和 y )
全过程的案例——self 贯彻类的始终!!也是实例的运用的本身!
给类设置默认值———在__init__中设置
动态添加类的属性,直接Car.weight='xx',此后的类、实例中,都会有weight这个属性!!!
1,通过实例,句点法访问实例的属性,直接修改即可。
2,在类中,新增一个方法,来对属性的值进行修改,一般
继承 初始设置很重要啊,包括
重写父类的方法,对于父类中的方法,如果有不符合子类情况的,都可以进行重写,这样python就不会考虑父类的这个方法了,优先考虑子类的方法
这个就是小类,将电动车中,关于电池的属性、方法单独放在这个类中,并将这个类Battery(), 用作电动车的一个属性 self . battery=Battery()
实例——属性——属性再调用小类(句点法调用它的属性和方法)
from car import Car , ElectricCar
导入整个模块,再用句点法来引用(好)
#自定义工作流程
from collections import OrderedDict
from random import randint
打开文件,要先赋予文件给变量file_object ,才能进行读取内容、等等操作
打开相对位置
打开绝对位置 注意,要在地址前面加一个 r !
with open(filename) as file_object:
with open....的代码块之外,要继续使用该文件的内容呢?
先设置一个 空的变量 ,对文本数据进行处理后,才能存储进去
文件内容读取后,存在列表里,修改列表里的数据(替换)
记得要在文本末尾加\n,否则不会自动分行
open后新加参数 'w' ,方法write (“xxx”)——输入内容
print 也可以之间在新创文件里写入!
#给文件新添内容,而不是覆盖原有内容,要用附加的形式“a”打开!!!
#使用异常避免崩溃————妥善处理错误,一般都在要求用户提供输入的程序中, 分析文本——分析alice文本包含多少单词——split()方法介绍
让程序检查可能出现异常的情况,
批量处理一系列文件—for循环 (调用同一种方法)
注意用法,以写入模式打开,dump存储数据——不同于txt的.write ( ) 以load读取数据——不同于txt的read
综合——两种情况合并在一个程序里 重构1 重构2
#json能将简单的python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。使用时,必须要引用import json
测试好处——确保代码质量
只为 测试方法 get_formatted_name 能否实现输出完整的名字这一功能!
类的测试 精品案例! 精品 调用一个函数,就能用到 函数方法+类 里的方法,
测试上面的类——较复杂!!! 测试类的时候,可以用set up 先创建要用到的实例、列表等等,
15.1绘制简单折线图 import matplotlib.pyplot as plt plt.show ( )
折线图!plot ( )
散点图!scatter()
设置好关联的x轴、y轴的列表!
1、choice从random中导入,并给予一个实参列表,它将从里面随机选一个元素! 重构函数————层层嵌套!简化流程!
调用类和函数——得到两个列表——x轴和y轴! 注意,rw . x_value 作为x轴的列表,并不是真实的列表,而是在函数中的列表,就是每次运行函数,该列表都会重置刷新,从头运行一遍,而不是不断地加入到 list 当中!!!
15.3 用Pygal 模拟骰子 Bar()是创建可缩放的矢量图的类!并创建该类下的实例!!——直方图! from pygal.style import LightColorizedStyle as LCS , LightenStyle as LS
设置骰子的类(通用的属性、方法),把面数作为可控形参! 列表解析!——全自动化处理数据!!!
移步到骰子终极版!
读入用 csv.reader ( f ),并存到变量里面! 关键,用enumetate,将某一行列表,设置为含索引的列表!
把表头以下的csv文件内容,依次遍历,提取出要处理的数据——
从csv中读取日期,用datetime处理,成为可视化对象,从而作为x轴来
对可能报错的csv、设置try - except 来检查! plt 可视化操作!!!——区分pygal中的可视化步骤!
16.2 json 收盘价走势 json文件的一般处理过程—— json . load ( f ) pygal的可视化操作——上下对比一下!
时间序列分析——发现趋势、周期性、噪声,预测未来从而做出决策
重构函数——收盘价均值(月、星期、星期几) 巧设 wd列表 [ ] ,内含各星期(也就是键的值),作用就是来匹配获取索引——将每个元素中,weekday的值 列表(有周期性循环的),转化为[ 1,2,3,4,...,1,2,3,4...] 这样有规律顺序的列表——后期将它对应形成其他列表的值!
设置成一个html,然后把先前的svg都依次加进去,注意格式!!!
17.1 api使用 网站 https://api.github.com/search/repositories?q=language:python&sort=stars
request.get ( url ) -----检查 status_code-----r.json( ) 存储到新变量中! 进一步处理,访问api的相关信息,比如api中数量、长度、键值、打印信息等等!
在导入api,检验,存为json之后,设置数据列表格式 增加工具提示,移动鼠标时显示信息——
调用其他网站的api——首先得找到,能读取的api列表!!! submisson_dicts是一个列表,里面的每个元素都是一个字典,显示了前30篇热门文章的title , link , comments 这些键值对!
PDF和 全套练习、答案 源代码
赠品:(也在上面附件)