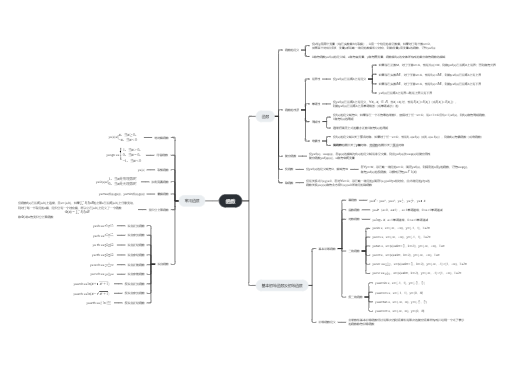
指语言中具有独立意义的最小语法单位
二元式:(单词种别,单词自身的值)
Φ是Σ 上的正规式,它所表示的正规集是 Φ , 即空集{ }。
ε是Σ 上的正规式,正规集:空符号串集合,{ε}。
是上的一个正规式,它所表示的正规集是由单个符号所组成成,即{}。
如果e1和e2是上的正规式,它们所表示的正规集为 L(e1)和L(e2) ,则有:
是上的一个正规式, 它所表示的正规集为:
是上的一个正规式, 它所表示的正规集为:
是上的一个正规式, 它所表示的正规集为:
如果正规式描述的正规集相同,则称等价
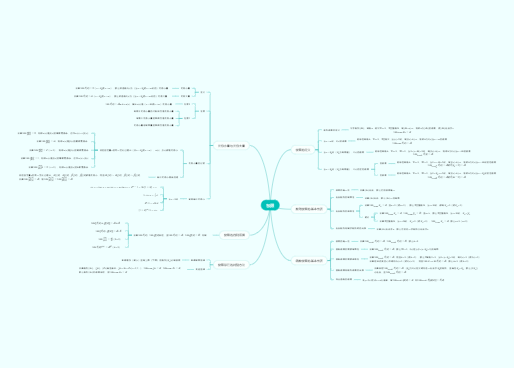
A | B = B | A
A | ( B | C) = (A | B) | C
A(BC) = (AB)C
A(B | C) = AB | AC
(A | B)C = AC | BC
Aε | εA = A
A* = AA* | ε = A | A* = (A | ε )*
(A* )* = A
将正规文法中的每个非终结符表示成关于 它的一个正规式方程,获得一个联立方程组
若 x = αx | β (或 x = αx + β ) 则解为 x = α*β
若 x = xα | β (或 x = xα + β ) 则解为 x = βα*
令 。
对任何正规式R,选择一个非终结符Z, 生成规则Z→R,并令S=Z。
若a和b都是正规式,对形如 A→ab 的规则 转换成 A→aB 和 B→b ,B是新增的非终结符。
对形如A → a*b 的规则,转换成 A → aA | b 。
不断利用 (3)和(4)进行变换, 直到每条规则最多含有一个终结符为止。
具有离散输入与输出系统的一种抽象数学模型。
有穷自动机有“确定的”和“非确定的”两类
是有穷状态集合,每一个元素称为一个状态
是有穷输入字母表,每个元素称为一个输入字符
是一个从Q×Σ到Q的单值映射
当前状态为,输入字符为a时, 自动机将转换到下一个状态 。 称为 的一个后继状态。
S∈Q ,是唯一的一个初态
Z⊆Q ,是一个终态集
对Σ*中的任何符号串β,若存在一条从初态结到终态 结的道路, 在这条路上所有的标记连结成的符号串 等于β,则称β为DFA M所识别(或接受)。
M所识别的符号串的全体记为L(M),称为DFA M所识别 的语言。
Q, ∑, Z 意义同DFA ,f 和 S不同于DFA 。
是一个多值函数,f( ,a) ={某些状态的集合}
,是非空初态集
NFA中,同一个符号串可由多条路来识别
DFA是NFA的特例
NFA和DFA的描述能力一样强
对于每个NFA M存在DFA M',使L(M)=L(M')
从语言单词的描述中构造出非确定的有穷自动机
再将非确定的有穷自动机转化为确定的有穷自动机
并将其化简为状态最少化的DFA
然后对DFA的每一个状态构造一小段程序将其转化为识别语言单词的词法分析程序
设I是NFA N的一个状态子集, ε-closure(I)(或ε-闭包)定义如下
(1) 若:s∈I , 则 s∈ε-closure(I)
(2) 若s∈I ,则从s出发经过任意条ε弧能到达的任何状态 s',s’∈ε-closure(I)
计算DFA M的初态ε-closure({x}),并置无标记送入Q'
寻找一个状态数比 M 少的 DFA M',使 L(M)=L(M')
有穷自动机的多余状态:从该自动机的开始状态出发,经任何输入串也不能到达的状态。
设 DFA M=,s, t∈Q,若对于任何当且仅当,则s和t是等价状态。
终态与非终态是可区别的
终态有一条到达自身的ε道路,而非终态 没有到达终态的ε道路
状态s和t必须同时为终态或非终态
对于所有输入符号a,状态 s 和 t 必须转到等价的状态里
1.将DFA M的状态集Q分成两个子集:终态集F和非终态集F,形成初始分划
。
2.对使用如下方法建立新分划:对的每个状态子集G:
(1)把G分划成新的子集,使得G的两个状态s和t属于同一子集,当且仅当对任何输入符号a,状态s和t转换到的状态都属于П的同一子集。
(2)用G分划出的所有新子集替换G,形成新的分划IINEw;
3.如果,则执行第4步;否则令,重复第2步。
4.分划结束后,对分划中的每个状态子集,选出一个状态作代表,而删去其它一切等价的状态,并把射向其它状态的箭弧改为射向这个作为代表的状态。
1.在M的转换图上添加两个结点:X结和Y结。从X结用ε连线连结到M的所有初态结点,从M的所有终态结点用ε连线连结到Y结,从而构成一新的非确定有穷自动机M',它只有一个初态结 X和一个终态结Y。显然,L(M)=L(M')。即,这两个NFA是等价的。
2. 逐步消去M'中的其它结点,直至只剩下X,Y结点。在消除结点过程中,逐步用正规式来标记相应的箭弧。消除结点的过程是很直观的,只需反复使用下图的替换规则即可。
右线性文法到有穷自动机
左线性文法到有穷自动机
有穷自动机到正规文法
第一种方法是用手工方式,即根据识别语言单词的状态转换图,使用某种高级语言,例如C语言直接编写词法分析程序。
第二种方法是利用词法分析程序的自动生成工具LEX自动生成词法分析程序。
首先,我们引进词法分析程序所用的全局变量和需调用的函数如下:
ch字符变量,存放当前读进的源程序字符。
token字符数组,存放构成单词符号的字符串。
getch()读字符函数,每调用一次从输入缓冲区中读进源程序的下一个字符放在ch中,并把读字符指针指向下一个字符。
getbc()函数,每次调用时,检查ch中的字符是否为空白字符,若是空白字符,则反复调用getbc(),直至ch中进入一个非空白字符为止。3.6词法分析程序的编写方法
concat()函数,每次调用把当前ch中的字符与token中的字符串联接。例如,假定token字符数组中原有值为“ab”,ch中存放着“c”经调用concat()后,token数组中的值变为
fer(ch)和degit(ch)布尔函数,它们分别判定ch中的字符是否为字母和数字,从而给出true或false。
reserve()整型函数,对token中的字符串查关键字表,若它是一个关键字,则回送它的编码,否则回送标识符的种别码10。
retract()函数,读字符指针回退一个字符。9.return()函数,收集并携带必要的信息返回调用程序,即返回语法分析程序。
dtb()+进制转换函数,它将token中的数字串转换成二进制数值表示,并以此作为函数值返回。